05.07.2019
23 min listen
With Mark Williams-Cook
Season 1 Episode 17
Episode 17: Robots.txt changes, diversity update and keyword research with Python

This episode we chat about Google's changes to robots.txt, how Google's diversity update is affecting sites, and keyword research using Python.
Play this episode
01
What's in this episode?
In this episode Mark Williams-Cook talks about how Google are dropping support for undocumented features of robots.txt in September and what effects this will have. Furthermore we talk about Google's diversity update and how its impacting sites. Finally onto some keyword research with python, a brand new (and free) tool built into Python.
02
Links for this episode
Searchmetrics analysis of the June core update: /us/site-diversity-update-analysis/
Scraping 'People also asked' on Google Search: /scraping-people-also-asked/
Unsupported rules in robots.txt: /2019/07/a-note-on-unsupported-rules-in-robotstxt.html?m=1
03
Transcript
Welcome to Episode 17 of the Search with Candour podcast recorded on Friday the 5th July 2019. My name is Mark Williams-Cook and today I'm going to be helping you through some of the Search news of the week.
This week there's new data on the Google diversity update and there's some analysis showing where the impact of that has been that's quite interesting. I want to introduce you to a really useful home-built and free keyword research tool I stumbled across during the week. Lastly, we'll talk about the changes Google has been making to how they're handling robots.txt.
The Google diversity update, I have an update on this for you. We mentioned the Google diversity update in Episode 13. If you missed that, it was announced on the 6th of June by the Google Search Liaison Twitter (@searchliaison) that said:
This site diversity change means that you usually won't see more than two listings from the same site in our top results. However, we may still show more than two in cases where our systems determine it’s especially relevant to do so for a particular search….
— Google SearchLiaison (@searchliaison) 6 June 2019
So that was the announcement that Google made on the 6th of June. They made it clear that the diversity update was separate from their big, much-talked-about June core update and since then we saw a little bit of initial findings from Moz that said the impact of the diversity update at least was minimal. At the end of last month I saw a really nice well-written report by Searchmetrics that published some analysis which showed actually the impact was maybe a bit bigger than we first thought. Again as always I'll link to everything I'm speaking about in the Search with Candour notes which you can find at search.withcandour.co.uk.
So, this post by Searchmetrics, I'm going to just read the most salient parts of this post for you. The whole thing is quite long if you do want to go through it yourself. The main question that they were trying to answer was “how common was it to find the search results flooded with organic listings from a single domain”, and they've said:

Basically, they're just looking at before and after the update, how many times is the same URL appearing lots of times in the top 10 and they've got a nice bar chart they've published that shows before and after the update. They say:
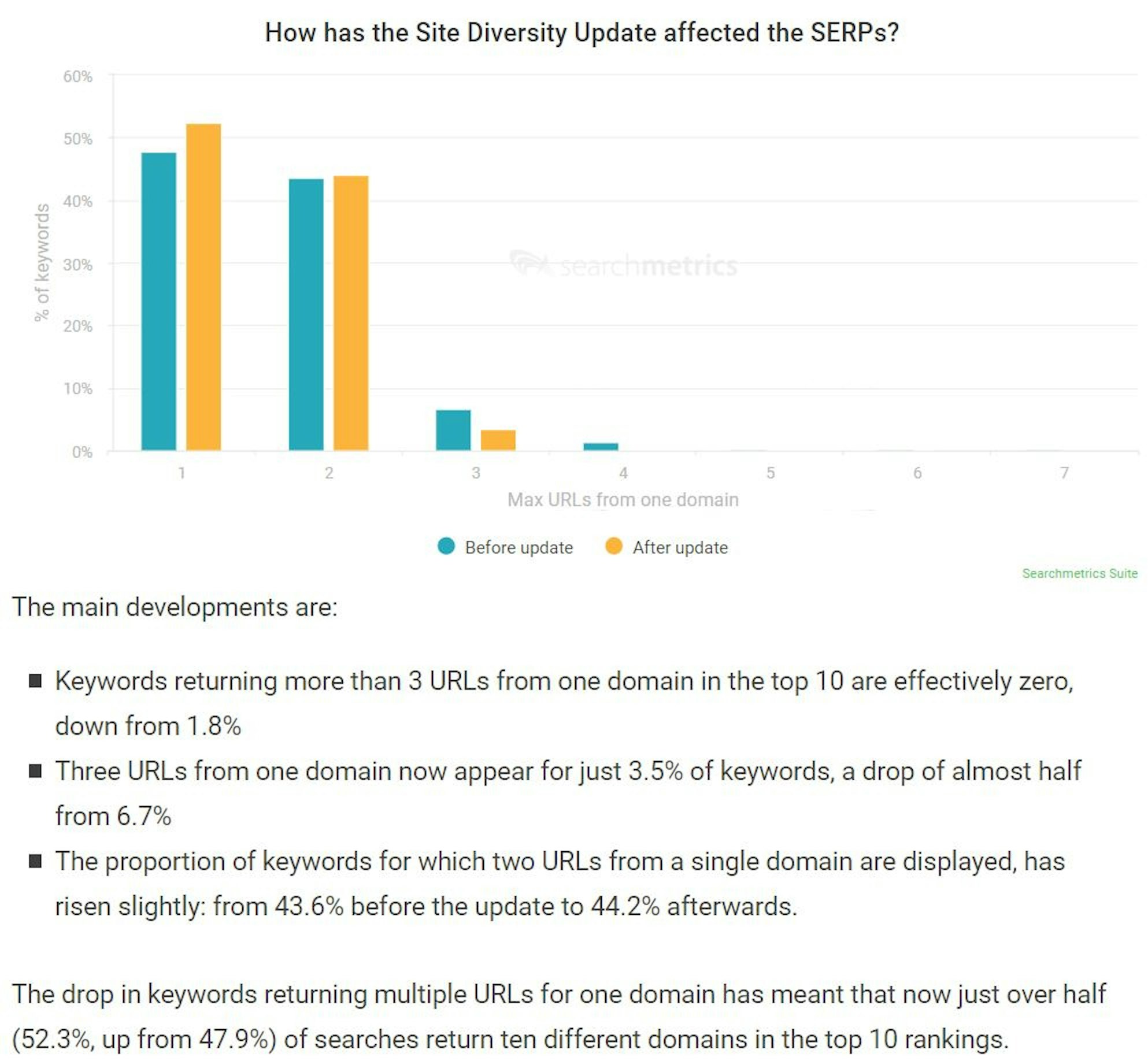
The post actually goes on to break down these results between transactional searches - so that's when there's a search with intent where someone basically wants to buy to transact. Informational searches are what it says, they’re just after information and comparing them as well to navigational searches so they're the searches when we're too lazy to type in the “www…” so you just Google the website name and click the first result.
I think that's important because if you're googling a navigational result, this is I think a situation where Google systems are very likely to come to the conclusion that it's very relevant to show more than two or three results from the same domain and unsurprisingly they've found that, especially in transactional results, this diversity update seems to have the biggest impact.
So, their conclusions from this is that smaller or niche sites have more chance to rank for keywords that used to be dominated by sites like Amazon. So that's actually a really great result for smaller businesses because that's one of the things you consider, especially if you're an e-commerce site, if you're overlapping with Amazon is if they're dominating that first page. Is it know worth the effort to try and shift them on those keywords?
They have also said:
“as the diversity criteria are only applied to organic results, SERP Features are given increased weighting. If you can (usually) only rank with maximum two organic results, then the boost from an additional Featured Snippet is all the more valuable. The same goes for image or video rankings.”
what they're talking about here is that we were told when the diversity update went live that it only applies to the standard organic listings – the ten blue links. It doesn't apply to the special results which might be featured snippets, they might be news results or as Searchmetrics have said image or video rankings. They're saying that now there's more value on these because you can't have necessarily positions 1, 2, 3, and 4 anymore so it's even more valuable to try and get those extra-special results as well.
Another consequence is a possible increased emphasis for the Amazon’s of this world on paid listings, if they can now only have two unpaid results then one way to ensure more top SERP presence will be investment in Google Ads or product listing ads which Google obviously won't mind at all. So that's very true, if they're reducing the amount of organic real estate that these larger organisations were enjoying to sustain the same amount of traffic and same amount of sales. The only way they might be able to do that is to start investing in Google's Paid platform which is obviously great for Google.
So, I thought it was an interesting update, something to watch out for if you aren't working at an SME, if you're doing e-commerce to maybe look at if you've noticed a change in your search positioning. It might not be because of the core June update; it might not be because you've done anything particularly well or different - it might just be because some of the sites that were above you were having multiple positions which have been taken away.
‘Scraping People also asked on Google Search’ is something I want to talk about because I found a really neat tool - just completely stumbled across it. I can't even remember how I found it and it's from a blog post by someone called Alessio Nittoli and they've done a blog post called ‘scraping people also asked’ on Google Search. So, people also asked, you have very likely seen it - it's the widget that's been introduced into the search results in 2015 and it gives hints about how search engines are trying to help users refine their search.
If you do an informational search you'll usually get this kind of ‘people also asked’ box where you can click on another question and then it will give you another search result, and it will set you down a tree system of other questions people also asked from that question. It’s particularly interesting with all the moves Google's made to becoming an answer engine as well over a search engine, and it gives you insight into how Google itself understands topics.
This script that Alessio is providing, Gquestions.py, is a Python script that you provide it with an initial starting point keyword and it will go to Google and do a search for this keyword, it will scrape the other questions that people also ask from Google and then it would take each of these questions people also ask and do that search and then get the next level of questions that people also ask.
So in the example he's given ‘flights’ as the initial keyword and it brings back ‘how do I find cheap flights’, ‘what is the best flight booking site’, ‘is it cheaper to buy a plane ticket last minute’ and ‘what is the cheapest day of the week to fly’ as the first four questions.
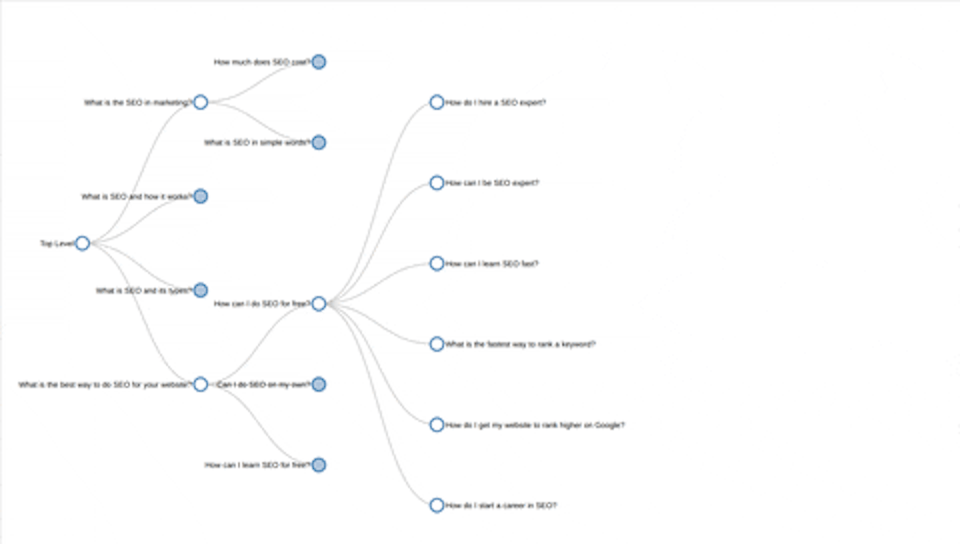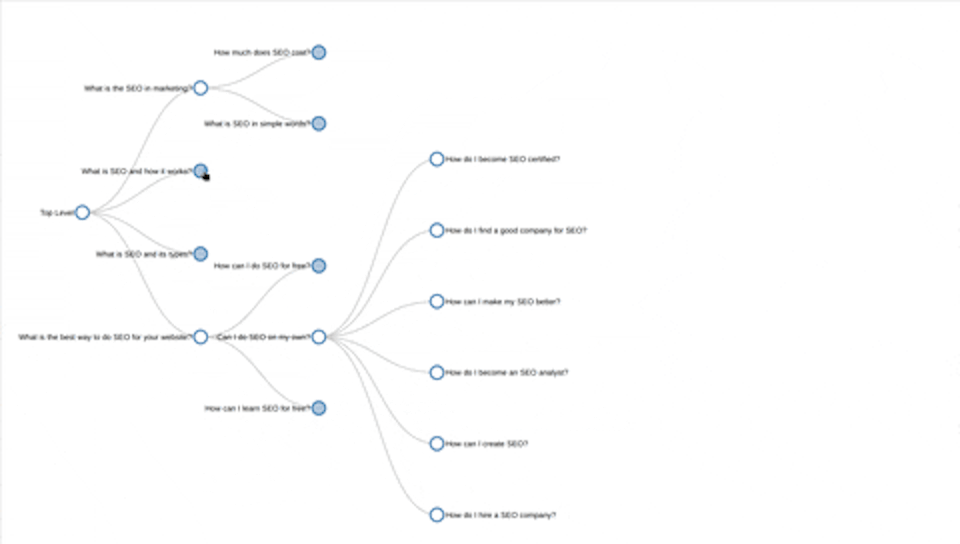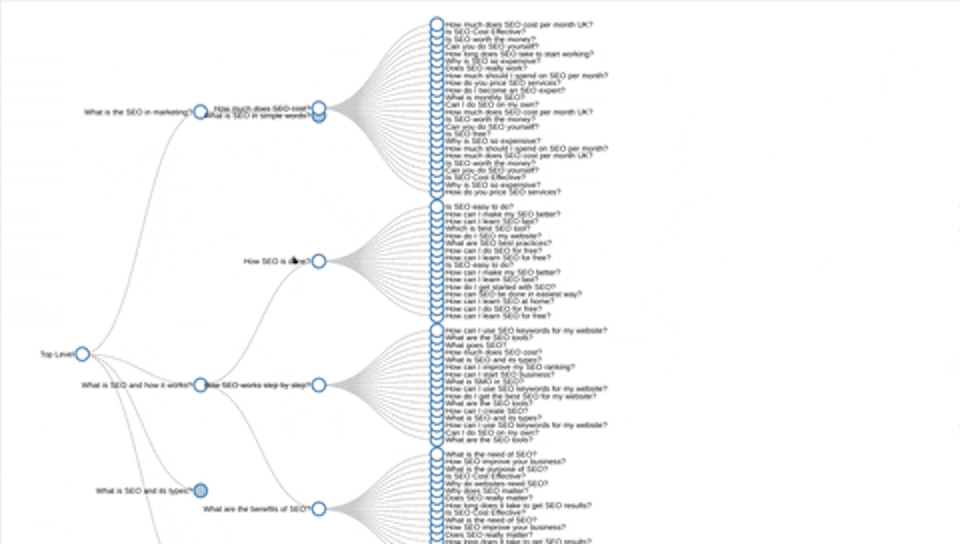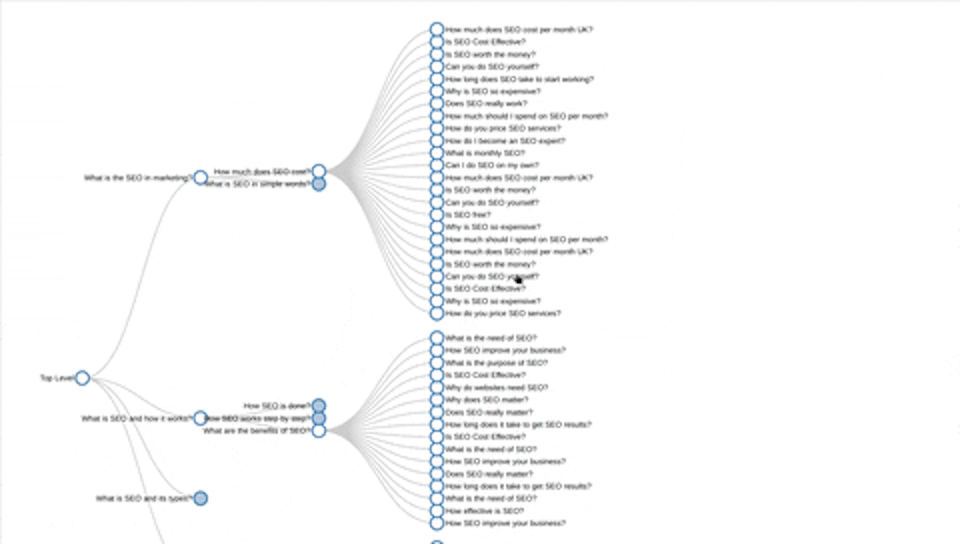
Then it breaks off from there. On the question ‘how do I find the cheapest flights’ there's another two tree branches that come from that, saying: ‘do flight prices go down at night’ and ‘how can I fly for free’ so, once it does this mining for you, not only does it save the results but it plots them on this kind of tree diagram that makes the information very easy to understand.
I think it gives a really good insight into how Google is actually understanding these subjects, and how questions are grouped together. Rather than doing keyword research and just having a huge list of things on that subject this helps you start breaking it down into, for example, when people are looking for flights, what people are looking at, what's the cheapest flight and there's a whole subset of questions from that. They start looking at what time to fly for instance, and there's a whole subset of questions from that as well so it gives you an idea of how Google's seeing these questions and topics and how they're all related together.
You will need a little bit of Python knowledge to get this up and running as it's a command-line tool - not particularly difficult. Alessio has provided fairly detailed instructions on the usage and there's loads of people online that use Python, so if you've got it installed on your Mac/Windows/Linux machine it should be pretty straightforward to get up and running. Don't be scared off just by the fact it hasn't got a nice pretty graphical user interface - it's a really neat tool.
Alessio then actually goes pretty deep into some natural language processing and talking about how you can actually use deep learning to automatically generate answers to the questions as well, maybe use them as like kind of live chat answers but even without doing that I think it's a really useful tool. It’s free and it's worth checking out!
robots.txt updates: we found out a few days ago that Google was open sourcing their robots.txt parser which was interesting news but not particularly impactful in terms of something maybe you should be doing as an SEO. But what did become interesting is they're actually now going to be removing support for things they were unofficially supporting before in robots.txt. So robots.txt is the text file that is helping us, as SEO’s and webmasters, control where Google goes on our site, where they crawl and actually could be used unofficially to specify parts of your site or specific pages that you didn't want Google to index.
So, while it was technically unsupported you could specify pages/sections on your site in the robots.txt you could say “noindex this part of the site”. Google published a post on the webmaster central blog, and again I won't read all of this I'm just going to read the part about them removing this support. They said:

What they're saying there is these rules that they were supporting were being used in such a way that contradicts other rules. Maybe people understood what they were doing so were potentially, I would guess, from the context of this people were accidentally blocking parts of their site from being indexed by Google without really knowing what they're doing.
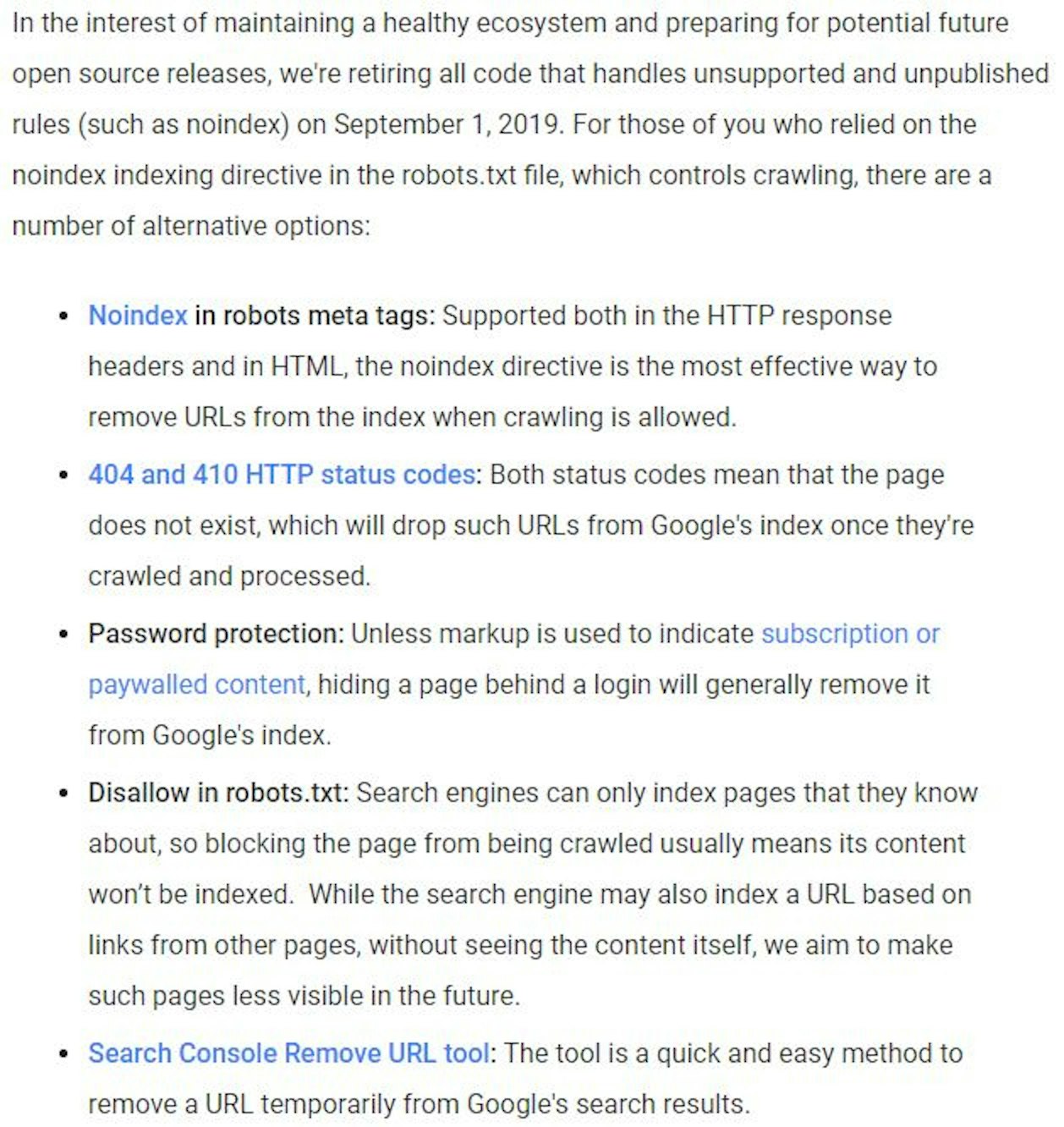
They list some different ways here, so I'll go through them quickly.
“Noindex in robots meta tags: Supported both in the HTTP response headers and in HTML”
So, they're saying the noindex directive obviously you can still use it but the documented supported way to specify for pages noindex is either through an HTTP response header or putting it on the page.
“404 and 410 HTTP status codes”
Both status codes mean that the page does not exist. 404 we've all seen those before - page does not exist, and 410 is the status code for the page if it’s removed, it's permanently gone, and they say which will drop such URLs from Google's index once they're crawled and processed.
“Password protection”
Unless markup is used to indicate subscription or paywalled content, hiding a page behind a login will generally remove it from Google's index. This one's quite interesting.
“Disallow in robots.txt”
Search engines can only index pages that they know about so blocking the page from being crawled usually means its content won't be indexed. While the search engine may also index a URL based on links from other pages, without seeing the content itself, we aim to make such pages less visible in the future. This is quite important because previously the disallow in robots.txt is there to prevent crawling but it did not specifically stop pages from becoming indexed and quite commonly you would see search results that it would return a page and it would say no further information about this page is available which would mean that it's been blocked from crawling, but Google has still indexed it. That's quite a common misunderstanding we found with many developers, that they think the disallow and robots.txt is going to stop pages getting indexed and it's not true.
So, they're saying it looks like there might be some tweaks here to make them less visible and make that actually a thing which I think will help everyone. Lastly:
“Search Console Remove URL tool”
The tool is a quick and easy method to remove a URL temporarily from Google's search results. If you do need to get a page out of Google's index quickly, you can request this temporarily removed by Search Console so that will very quickly remove it but unless you've specified it's noindex and you don't want it in there it will come back in when it gets crawled again. So, that's just a way to remove pages before you have to wait for Google actually to crawl them to see your noindex tag or header response.
This announcement got mixed reactions from the SEO community; many people were pointing out that using noindex robots.txt was never officially supported - it never has been supported by other search engines like Bing so why have you been using it at all. Others have pointed out that the support for noindexing pages in robots.txt was actually really helpful and I'm kind of on this side of the fence to be honest.
The current support officially supported methods and the future only methods of noindexing pages of getting it to return the noindex in the HTTP header or getting implemented on page require development teams to make changes to actual website pages they may be working on, or may have the repercussions or impacts. While that in theory sounds a very simple thing to do and the risk is low of doing these kinds of things, in actual reality of working with businesses day-in day-out working - especially with larger companies with development teams, with priorities, with ticket systems, these changes can get put right at the back of the queue because the fact is they're happening on pages that are going live.
It needs to be tested, it needs to be triaged so they can take months and it is easier to get a developer to make a change to a robots.txt file than anything that's going to impact the rest of their development flow. It's very, very unlikely you're going to break anything updating a robots.txt - at least in terms of the stuff they're working on. I've seen quite big companies use the robots.txt to control noindex just because I think it's a way to skip their dev flow which is of course kind of their problem but, in reality that was helping a lot of people and Google are saying that the rules are allowing more people to hurt themselves which nobody else has seen that data apart from Google so that's hard really to comment on.
My guess would be it's probably going to be people who aren't doing SEO or certainly not doing it properly if they're writing robots.txt rules that are contradicting each other and blocking whole pages from the web and they haven't even noticed. It's unlikely that they're going to get any meaningful rankings anyway, I would guess. Although that's not what Google's aim is, they don't want to make it difficult for people to do that - the idea is you just build a website and Google be able to rank it so they've made it they've made a decision there.
We're going to have to live with it either way, you've got until the 1st of September if you are relying on this method. I've had some questions when I spoke about this earlier on social media from people running WordPress sites, if you aren't running WordPress and you've got you know one of the popular SEO plugins (something like Yoast) none of these should be using robots.txt with noindexing. You don't need to worry about it or changing anything and I suspect those who will be affected will know they're about to be affected but if you're not sure, check!
That's everything I have time for this week. I do hope that you found it helpful and that you've had a great week! I just want to give one quick shout out to Daniel Brooks and Dom Hodgson who came last night and did two brilliant talks at SearchNorwich - at our one-year anniversary of our SEO search meetup in Norwich.
Thank you so much guys, the talks went down really, really well and I will catch you all next week. We will have the next podcast going live on Monday the 15th of July and that's everything I'm Mark Williams-Cook and I hope you have a good week!
