27.04.2020
34 min listen
With Mark Williams-Cook
Season 1 Episode 57
Episode 58: Google (no)index, free shopping feeds and featured snippet traffic loss

In the episode, Mark Williams-Cook will be covering Google (no)index: Issues with Google indexing new content and some things you may not know about site: cache: and x-robots, free shopping feeds: Google's huge announcement that it will make inclusion in shopping feeds free and featured snippet traffic loss: A quick dive into the Moz experiment that demonstrated removing featured snippets may be detrimental to your traffic.
Play this episode
01
What's in this episode?
In the episode, Mark Williams-Cook will be covering Google (no)index: Issues with Google indexing new content and some things you may not know about site: cache: and x-robots, free shopping feeds: Google's huge announcement that it will make inclusion in shopping feeds free and featured snippet traffic loss: A quick dive into the Moz experiment that demonstrated removing featured snippets may be detrimental to your traffic.
02
Links for this episode
03
Transcript
MC: Welcome to episode 58 of the Search with Candour podcast! Recorded on Thursday the 23rd of April, my name is Mark Williams-Cook and today we're gonna be talking about Google indexing, no indexing and cache, Google's announcement they are making shopping feeds free and a study on how Rich Snippets can impact traffic.
There's a whole bunch of indexing stuff I want to talk about today. Firstly, I picked up a story this week on search engine land that said Google is not indexing new content again and this is actually something we covered almost a year ago (Episode 5), to the day, I think it was about a year and a week ago where Google was again, in 2019, having issues just indexing new and fresh content. The same thing seems to be happening again in the search engine land article they've got some examples of doing site queries for sites like the New York Times and Wall Street Journal and then going and setting these options to show results from the last hour only and actually a lot of these search results were coming back blank. Same with search engine land posting stuff and then checking 20 minutes later, it's still not in the Google index, that may sound quick but normally these articles will get indexed and they'll be their ranking within minutes certainly not 20 minutes or an hour.
So Google is aware of this issue, they've had these issues before. Last time they said they had it fixed, but it actually took a week to fix. It looks like it's been resolved now, however, I did see in the thread on Twitter where it's reported - I’ll link to in the show notes - that other people were reporting similar errors to last year, where previously indexed pages were actually dropping out from the index as well, so it may well be that like last year, there's not just an issue with Google indexing new content but last year they did have an issue where already indexed content was just dropping out and they had a large chunk of their index drop out, so I'd be surprised if that kind of infrastructure-ly isn't related. But that's important for, if you are running a site where you're getting organic traffic to very timely content - so you're publishing things and you're expecting and normally you get traffic within kind of minutes or hours, if you've seen a dip in search traffic that could well be why, so it's very much worth checking your Google search console as to whether those pages are included in the index.
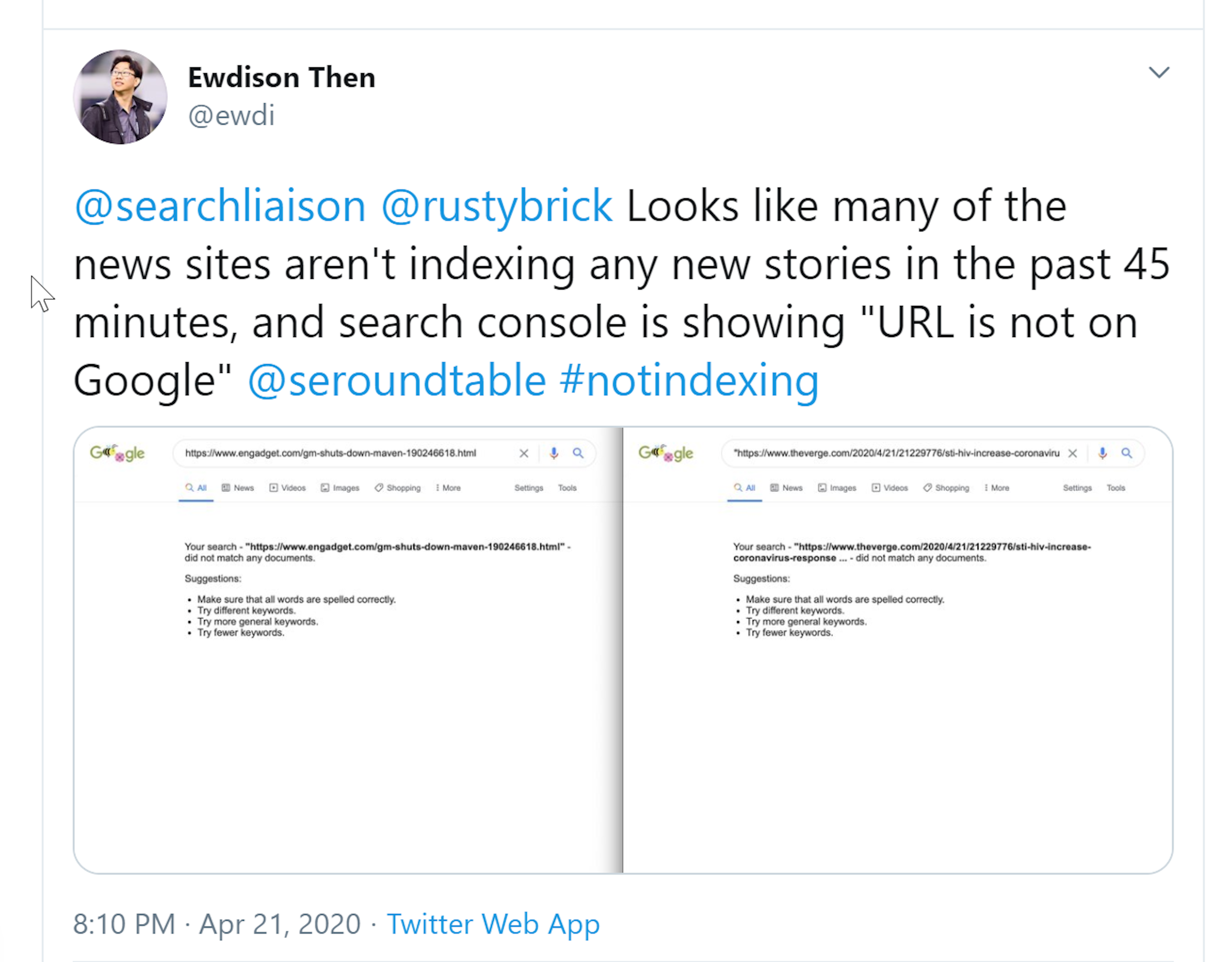
That last piece on checking whether your sites or specific pages rather of your site indexed is actually quite timely for me. So I wanted to talk about Google's index, no indexing and cache and site queries and stuff, because I've learned a new set of technical SEO things in the last couple of weeks that are related to indexing, which is pretty new for me and that these things are fairly important I think from how we use Google as SEOs and what tools we choose to use and decisions we're making, just because I thought I knew this area very well but like with many things in SEO, it turns out you don't know everything all the time and I'm happy to admit that and I'd like to just share with you what I learned over the last couple of weeks, because I'm quite confident I'm not going to be alone in that I didn't know these things.
So the first thing to do I guess with indexing is I saw a thread on Twitter that John Mueller from Google was in, where he stated that site colon queries, that is if you go to Google and you type site colon and then you put in your domain or subdomain and domain, you will only get search results from that domain. So this historically was used by SEOs to see which pages were included in the index, it's still used to check or to do internal like searches through Google, so if you want to see which of your pages have title tag optimizations for something you can combine it and say do a site colon, your site dot com and then you can use the operator in URL colon and check for like a phrase that you want to check your titles for and that search result will only return results from the domain you've specified in the site operator. So that's all like super basic, super old, everyone knows this and I've known for probably a couple of years now and I've discussed it with other SEOs that using site colon and then type in your domain dot com, dot co.uk, wherever it is, you will get a list of pages back from Google so it’ll say you know pages 1 to 10 of you know 2000 or however many, and we've known for quite a while that that number it gives you is not an accurate representation of how many pages are indexed. So it is very usual that you will see some variance in that maybe 5, 10, 20 percent, whatever so I I must admit I still do use that sometimes as a very quick check when I don't have access to internal tools or verified tools, I should say, like Google search console or Google Analytics, so you can do a site colon and then a domain search and what I'm looking for is, if it says you know one of ten pages but I know the site's got 10,000 pages, then I know I've very likely got an issue and the reverse is also true - if I know a site's maybe got 50 pages and I do a site colon query and you get ten thousand pages back, then you've probably got some other kind of technical SEO issues. so I still use it, sometimes, to do those kinds of checks, which I hope other SEO people do, but I certainly do, I'll admit it.
Here's what's really interested me: I saw on this thread that John Mueller was posting on to help someone out, he basically said if you're looking at site colon queries we like to be helpful and show what you're asking for even if that's not how it's currently indexed. The cached page often shows the correct URL, don't use site queries for debugging. So the takeaway from this is that site colon queries can return pages that are not included in Google's index or at least they're not gonna be - Google knows about them but they're not going to be returned in terms of they're not in a search index, they're not going to appear in a natural search and I didn't explicitly know that, so that means if you have pages that are specifically no indexed perhaps or if you have pages that Google has maybe crawled, discovered, but has decided not to include in their search index these may come up when you use a site colon query and I thought that was that was quite interesting. If you want to check if something's in the index you can't, for instance, do site colon and then paste the full URL - that's not an accurate check. So he did say the cached page often shows the correct URL. So I thought okay, and I've seen this before and I've done posts about it where I've seen discrepancies and I've talked about it between what Google search console says is indexed, what Google returns with a keyword search, what Google with a site query and what is or is not shown in the cache, so I thought okay, well maybe from an external point of view, again without access to verified tools, maybe a cache colon search would be a better way to do this.
I then saw Martin Split again, another lovely guy at Google, who's got a whole series of JavaScript videos. I've spoken about him before, really helpful to webmasters, tweeted something that was related the same day and he said, where does the obsession with the Google cache come from? Why are people treating it as a tool to check their pages with JavaScript content when it basically says it doesn't work as a testing tool and it doesn't tell you anything - what he's saying that is we know that there's this two phases of indexing or at least rendering, I should say, whereby Googlebot will come around discover pages it will look at the raw HTML and it will index those and then those pages go into a render queue and if they've got JavaScript at some point hopefully the JavaScript will be rendered and then put into Google's index.
So again, historically I had and used the Google cache colon site operator as a way to try and get a view of how Google was understanding pages when I didn't have access to the URL inspection within Google search console, although I'm aware there are other ways to do it. And what Martin says here is, again, this isn't necessarily reflective of how Google understands the page content. I did talk to Martin a little bit about this, saying that I personally don't think that historically the Google documentation and communication around all of this stuff around site queries, around cache, Javascript rendering, has been particularly clear and certainly, from an anecdotal point of view, I've done my own tests, I've seen other people do tests where at least those things match up in that when we have used the cache operator to look at what Google has in its cache, that seems to reflect what it will rank for in terms of JavaScript rendering and visible content.
So the very basic experiment that I've done and shared, multiple times, is just made a page in HTML with a specific page title and then on that page I use JavaScript to just update the page title and the first thing I noted about this was the time lag between the HTML title appearing in Google and the rendered JavaScript changed title appearing in the Google search result was 24 days, which led me to believe that in this instance, not particularly popular or authoritative blog and that it took Google 24 days before it got around to rendering that. And that, as far as I could see, he was what was correctly reflected in the cache, in that if I searched for the string in the title in Google that was put in by JavaScript, it would not rank until that page, at least within a 24 hour window, was in the cache. So this is maybe the risk of doing these kinds of experiments as well, which is lots of websites obviously are different, the architecture I can't even begin to fathom how complex the code paths and architecture are at Google to handle, you know the web at this scale, and that this is like a tiny single data point in the never moving flux of stuff, so it's maybe unfair to draw conclusions and say well this definitely works this way, but Martin is saying that using this cache colon command is not a good way to understand if and how Google sees the content reliably. Again if you don't have access to some other tools, I think it can be used in a pinch because it's certainly better, in my experience, than nothing, but we may have to start thinking about staying in step with the tools Google are putting out and trying to use them a bit more.
The other thing that when I spoke to Martin about this was I asked him where he would recommend I read a bit more about this and he gave me a couple of links to Google Docs, which again I'll provide in the show notes - so all the show notes you can get at search.withcandour.co.uk - and one of the documents he pointed me to was this Google documentation on JavaScript SEO basics and I read through that again, it's certainly changed since I last read it. The thing that stuck out to me was again, this very clear statement that said: if Googlebot encounters no index it skips rendering and JavaScript execution. Again, this makes perfect sense to me but as an SEO, doing SEO for 15 or so years, I had never actually heard anyone specifically discussing this up until this point. I say it makes perfect sense because the reason Google has this cue, this rendering cue, for pages to do JavaScript is that it's a very or is a comparatively resource intensive thing to do. They don't have the computing power to just on-the-fly execute all the JavaScript on the web yet, as we go so there is this queue. so it makes complete sense whereby, if you're saying to Google, look this page we don't want it in the index, there's very little point in Google then actually bothering to do that resource intensive task of trying to execute, render the JavaScript and and see what's there because it's not going to be in the index anyway right. Interestingly this conversation had sprung up because Martin was actually discussing with someone saying, okay so if the no index is in the tag, in the page, then they do this thing where they definitely just skip the JavaScript rendering and execution, that's fine. So someone then asked what happens if the no index tag is added itself by JavaScript? So the page is normal, it's going to be indexed but then with JavaScript you add the no index tag and Martin helpfully did clarify that in that instance Google would like retroactively respect that no index tag, so it means you can add no indexed tags through JavaScript for instance through Google tag manager. So what's happening in this instance is Google crawls the page, the HTML, it goes into the rendering queue, it renders the JavaScript, it then sees that this page has a no index tag and it will actually then no index that page. I guess what would happen is then it would have to keep going back and occasionally checking to see if that's still the case if it is added by JavaScript.
So this conversation was going on and then Tim Bridges on Twitter, whose @browserbugs posted a comment that really interested me and he said I assume that if I did that in the headers you wouldn't waste your time on the HTML. So meaning if we put in the X robots header, the no index tag would Google even bother looking at the HTML for that page because if we're saying again, don't index this page, why would Google bother to do that. So, I actually thought that's quite an interesting, really specific edge case scenario of, okay we know that Google will look at the HTML of a no index page and we know they do, at least to begin with, follow links on that. They have to look at the HTML of the page because the no index tag is on in the HTML, so if they didn't do that, it wouldn't actually see that. So I asked the question on Twitter - if we've got a page A and page B and page B is linked, only from page A, and page A is declared as no index via the X robots header, would page B get indexed - so what I'm asking is, if there's a page, that's fine, it can be indexed, but the only way to get to that page as a crawler, is from a page that's no indexed and that no index is set in the X robots in the header, will it find that link and will it get indexed? Because in reference to Tim's question, if the answer was they don't bother with the HTML then it would mean that Google would land on page A and it would get the X robots back and say oh okay this page is no Index so I'm not even gonna bother passing the HTML on this page, I'm not even gonna bother adding any links on this page to my crawl queue.
So I asked this question and I had 1071 votes on this - 63.6% of people said yes, it would get indexed; so they think that Google, despite having a no index in the X robots, would look at that page and would look at the HTML and follow the links. 20.1% said no, that Google for whatever reason would not follow or will not discover page B after seeing the X robots no index. 2.9% very honestly said they don't know and 13.4% just wanted to view the answers because they don't have an opinion. So the overwhelming majority there are thinking it will get indexed. There are lots of people asking follow-up questions around how long is the page no index for because there's this very well-known trotted out line about if a page is left as no index for quite some time, then Google will treat all of the links on that page as nofollow links. So links that don't pass PageRank. And I found that quite interesting when people were asking, how long is this page been left is no index, because as far as I have seen through my research is nobody has ever published a specific amount of time between when a no index pages links will be followed, till when they become unfollowed - it may well be because there isn't a specific set of time and it relies on a whole bunch of other factors, it may well be that people don't know, but I don't understand why we need to know that if we've got no idea whether that means minutes, hours, days, weeks, months, or years or what the context is to the rest of the site. But most people decided that we will get indexed, so I've actually set up a test to do that now and actually two other people have as well, so it’ll be interesting. We've just set up some brand new pages that haven't been visited in browsers and not in sitemaps or anything, they're just little hand coded HTML pages, they shouldn't get discovered in any way except through crawling. So we've built pages for them and built two experiments, well I’ve done two experiments. One, which is linking from a page that's no indexed through a tag in the HTML which I would expect it to follow through and another page that's linked only from a page that's no indexed in the X robots header which I don't know about. I think it probably will get discovered, but it'll be really interesting to see, so I will publish those results when I have them and everyone else's as well.I just thought that was it's quite a long kind of ramble but some really interesting stuff about site no index, cache and how Google is handling that.
Now on to Google's announcement about Google Shopping becoming free, which is pretty much what it says on the tin, that's quite a big announcement. so up until well apart from right at the beginning when Google allowed us to submit feeds way back when to Google base for most of recent history to be part of Google Shopping ads, to have PLA s - that's product listing ads - you have had to submit a feed through Google Merchant Centre and then of course, you have to pay. Google has done an announcement on the 21st of April by Bill Reedy, who's president of commerce and it's titled “It’s now free to sell on Google” and this is what Bill has to say: “The retail sector has faced many threats over the years which have only intensified during the coronavirus pandemic, with physical stores shuttered, digital commerce has become a lifeline for retailers and as consumers increasingly shop online they're searching, not just for essentials but also things like toys apparel and home goods, while this presents an opportunity for struggling businesses to reconnect with customers many cannot afford to do so at scale. In light of these challenges we're advancing our plans to make it free for merchants to sell on Google, beginning next week search results on Google Shopping tab will consist primarily of free listings, helping merchants better connect with consumers regardless of whether they advertise on Google. With hundreds of millions of shopping searches on Google each day, we know that many retailers have the items people need in stock and ready to ship, but are less discoverable online. For retailers this change means free exposure to millions of people who come to Google every day for their shopping needs. It's for shoppers it means more products from more stores discoverable through the Google Shopping tab. For advertisers this means paid campaigns can now open with free listings, if you're an existing user of merchants enter shopping ads you don't have to do anything to take advantage of the free listings and for new users of merchants centre will continue working to streamline the onboarding process over the coming weeks and months. These changes will take effect in the US before the end of April and we aim to expand this globally before the end of the year. Our Help Center has more details and how to participate in free product listings and shopping ads. We're also kicking off a new partnership with PayPal to allow merchants to link their accounts, this will speed up our onboarding process and ensure we're surfacing a highest quality results for our users and we're continuing to work closely with many of our existing partners that help merchants manage their products and inventory including Shopify, WooCommerce, and BigCommerce to make digital commerce more accessible for businesses of all sizes. Solutions during this crisis will not be fast or easy, but we hope to provide a measure of relief for businesses and lay the groundwork for a healthier retail ecosystem in the future.”
So that's massive news for if you have an e-commerce site, especially if you've got a small SME on Shopify or something. What Google is now saying is that these really high intent shoppings ads, which do work really well on Google ads, will now mainly be free organic listings. So to get these, if you haven't already, you need to sign up to Google Merchant Centre and you need to get a product feed delivered through Merchant Centre. A lot of e-commerce platforms, like WooCommerce, like Shopify, like Magento, all the ones we've been speaking about over the last few weeks, generally will all have either free or a lot of them are paid plugins that will generate this product feed for you, based on the information you've already entered in your site, about your products. It'll also keep them up to date in terms of things like availability and stock levels. So actually once you've got it set up, you've got that feed working and verified there isn't too much ongoing work there.
How that impacts paid search is still unclear. From speaking to other people, working in both SEO and PPC, I think it's probably accurate to take a slightly cynical view on Google's timing of this and their reasons for doing so. Interestingly, when people talk about Google and Google's competitors - Google's biggest competitor isn't really another generic search engine like themselves, Google's biggest competitor generally is seen as Amazon - so because of the market influence that Amazon has, a lot of people with purchase intent actually will start their shopping experience at Amazon. So they won't do a Google search for their kids jigsaw puzzle, they will actually just go straight to Amazon, do a search there because maybe they've got a prime account or whatever, they trust that site. Having that group of people with high purchase intent are obviously very valuable people, very valuable searches not on Google, will adversely affect how many people pay for ads basically. And I think Google's come to this tipping point conclusion of well, we would rather have people stay on Google and have a chance of interacting with a paid ad, then sidestep and just go straight to Amazon because the downside of the Google shopping experience, currently, is that because it is all paid, you actually have a very narrow window of retailers that are run there, in comparison to all the ones that could potentially sell you that type of product. Which means that as a consumer the user experience is potentially worse for you, in that because Amazon's e-commerce focus and it's so big generally, you can get a very wide range of what you're looking for. So I think the industry feeling is actually, this is a longer term move by Google to challenge Amazon in terms of becoming a one-stop place for e-commerce. So if they can position this correctly and it has a blend of sponsored and organic results, like the like Amazon search results do right, because when you search on Amazon you see at the top there are sponsored results and there are the organic results, if Google can provide this similar experience, they may be able to retain or even take more market share of Amazon. Either way, really interesting - if you're in the u.s., coming before the end of April for everyone outside the US at the end of the year.
I wanted to finish on an article I read, just before I recorded this podcast, about Google featured snippets and this is on the Moz blog, it's a blog post under advanced SEO by Cyrus Shepherd and I will link to it. it just caught my eye because essentially what they have done is a pretty neat experiment on what happens if basically we give up our featured snippets. featured snippets, as the post explains, used to be almost a no-brainer because if you want a featured snippet it was quite common that you could have this position of 0 at the top of the page and you could normally secure the number one position or at least in the top few results as well; so you essentially get over double the presence on the on page 1 of Google. Back in January, as we talked about on the podcast, Google was talking about basically deduplicating search results, meaning if you have got a featured snippet, your normal search result is now going to disappear and this was quite interesting because there had been some people suggesting, some studies suggesting, that actually featured snippet weren't so great because a lot of the time, they satisfy at least enough of the searches intent where maybe they don't click and people had been historically trained to click on normal search results.
So the question there was, well if we've got a choice now between having a featured snippet or having a normal search result which is going to get us more traffic? So on the Moz blog, they basically worked with the team at Search Pilot and devised an a/b split test experiment to remove Moz blog posts from Google featured snippets and measure the impact on the traffic. They did so by using Google's data and no snippet tag, which again we've talked about on previous episodes, and the hypothesis was that basically the pages would lose their featured snippet and the regular search results would show below. and the in the results from this were actually quite significant and it seems, so after adding the data snowed no snippet tagged the variant URLs did lose their featured snippets very quickly and and they measured a estimated 12% drop in traffic for all of those pages, where they had removed the featured snippet, and that was with a 95% confidence level.
The other thing I thought was really interesting at the end of this test was after they end of the test and they kind of put everything back to normal, they actually failed to win back a portion of the featured snippets that they originally ranked for and I find this hugely interesting because what's happened here, Google has decided that this page for whatever reason is the best page to give a featured snippet and then you say to Google, I don't want you to show a featured snippet so Google's like fine I will remove you and I'll replace you with this site. When you then say, Google actually no it's fine you can use the featured snippet, what's changed Google's mind there? It's now decided that well I'm actually ranking this site, so I'm going to stick with this one thank you - even though it's previously decided that that snippet was the best one, it's now sticking with its new one. and that's kind of I think a really interesting thing to think about in terms of well, is it because Google now... has it been a negative signal that that site's said you're not allowed this, has that had some kind of long-term echo effect on that URL that Google's gonna be less keen to use it as a featured snippet? Is it because once Google's run with a featured snippet, there's a set cycle before it will kind of check which one it can replace it with? I'm not quite sure on what the answer is there, but I’ll link to the experiment and the show notes I think it's really interesting to read through, you can get it at search.withcandour.co.uk.
That's everything we've got time for in this episode, we're gonna be back on Monday May the 4th. So May the 4th, it's gonna be Star Wars day for those who are fans, and I hope everyone is doing well in their various states of lockdown and quarantine. As I said, we will be back on Monday. I've asked a few of you, if you do enjoy the podcast - I don't really normally ask people to do this because it's kind of annoying, but if you can give us a rating, if you like it I would really appreciate it, helps us get the word out, get more listeners, more interactions, all that stuff.
