04.05.2020
42 min listen
With Mark Williams-Cook & Dan Taylor
Season 1 Episode 59
Episode 59: Backlinko SEO study with Dan Taylor

In this episode, Mark Williams-Cook will be talking to Dan Taylor about the Backlinko 11.8M Google Search result study, the SEO community's reaction and Dan's thoughts on how useful the study in context is helping people rank better.
Play this episode
01
What's in this episode?
In this episode, Mark Williams-Cook will be talking to Dan Taylor about the Backlinko 11.8M Google Search result study, the SEO community's reaction and Dan's thoughts on how useful the study in context is helping people rank better.
03
Transcript
MC: Welcome to episode 59 of the Search with Candour podcast! Recorded on Friday the 1st of May. My name is Mark Williams-Cook and today we're going to be talking about the Backlinko correlation study search results of 8 million search results and to do that we are joined by Dan Taylor, lead technical SEO consultant count director Salt agency, hello Dan.
DT: Hi Mark, how are you doing?
MC: Very good thank you. Thank you so much for joining us. So Dan, can you give everyone, I mean I know you, but do you want to give everyone a quick intro to sort of who you are what you do and a little bit of your background.
DT: Yeah sure, as Mark said, I'm Dan, I work as an AD and lead tech SEO consultant for SALT agency, based up in Leeds in the UK. I got into digital marketing, about seven, eight years ago fully; previous to that, I actually work on fishy docks as a fishmonger and fish markets.
MC: No way, I did not know that about you.
DT: Yeah so I've actually learned a hell of a lot about fish and then took absolutely no knowledge in the digital world after University. I’ve been working at Salt now for 4 years this month. I work with quite a range of clients, mainly across the US, tech and SAAS sectors, but then also quite heavily in e-commerce and travel as well. Also spoke at a few conferences like tech SEO boost, Brighton SEO main stage. Also won the inaugural tech SEO boost research competition, for a little foray into this thing called edge SEO and using CBN's to do transformations and you might also see in your mind with being is sloth.cloud, hreflangchecker.com and various other pies that I've got my fingers in.
MC: So I was actually gonna say to everyone, so edge SEO technical SEO and specifically edge SEO is something you're always at the front of my mind for. So I mean I've learned quite a lot from you about edge SEO and you know you’re very keen to tell me that CloudFlare workers aren’t service workers and you mentioned sloth.cloud there, do you want to just briefly describe what that is for people that haven't heard of it?
DT: Yeah so essentially site SEOs is not really anything new we've been it's been something that's been around so of 2014-2015 that we've been able to do hard-coded on my lambda edge servers, things like that but essentially the advent of Cloudflare workers meant that we could easily do transformations through the CDN which overcome a lot of technical debt issues and other issues, we're actually getting technical SEO implemented basically. So sloth.cloud essentially was actually born from - we built a generator in-house to quickly do code. I mean my developer who is the mastermind kinda got really bored of me asking constantly for tweaks, so he stuck the generator behind a nice UI and then I went, well can we just roll this out and we just open it all for everybody to make an account, login and generate edge worker codes really for free.
MC: I think that's how a lot of good products are born. so when I was speaking to Stephen, who's one of the cofounders of content King, there was a similar story there I think of essentially developers and SEOs getting fed up each other from lots of very similar requests until the developers just started coding solutions to make the SEOs go away they decided to wrap it up in a product. So that's sloth.cloud, it's free check it out.
So Dan, what I've got you here to talk about is something a lot of people online are talking about, which is the backlinko correlations study. So for those that haven't seen it yet, on the 28th of April, Brian Dean from Backlinko tweeted about a new study that they had done and this week said, we analysed 11.8 million Google search results here's what we learned about SEO. Important, so there's a list of things that they consider important - domain rating, short to URLs, page Authority, comprehensive content, and backlinks and then they've listed things for things which were “not important” - which were schema, site speed, word count and title tags. Now this tweet, as I'm looking at it now, has 425 retweets and 1.5 thousand likes and I want to talk about it for a couple of reasons - so backlinko, the website as it is does rank for a lot, it does drive significant traffic, so whether you agree with what they're saying or not, they are quite influential when it comes to SEO content.
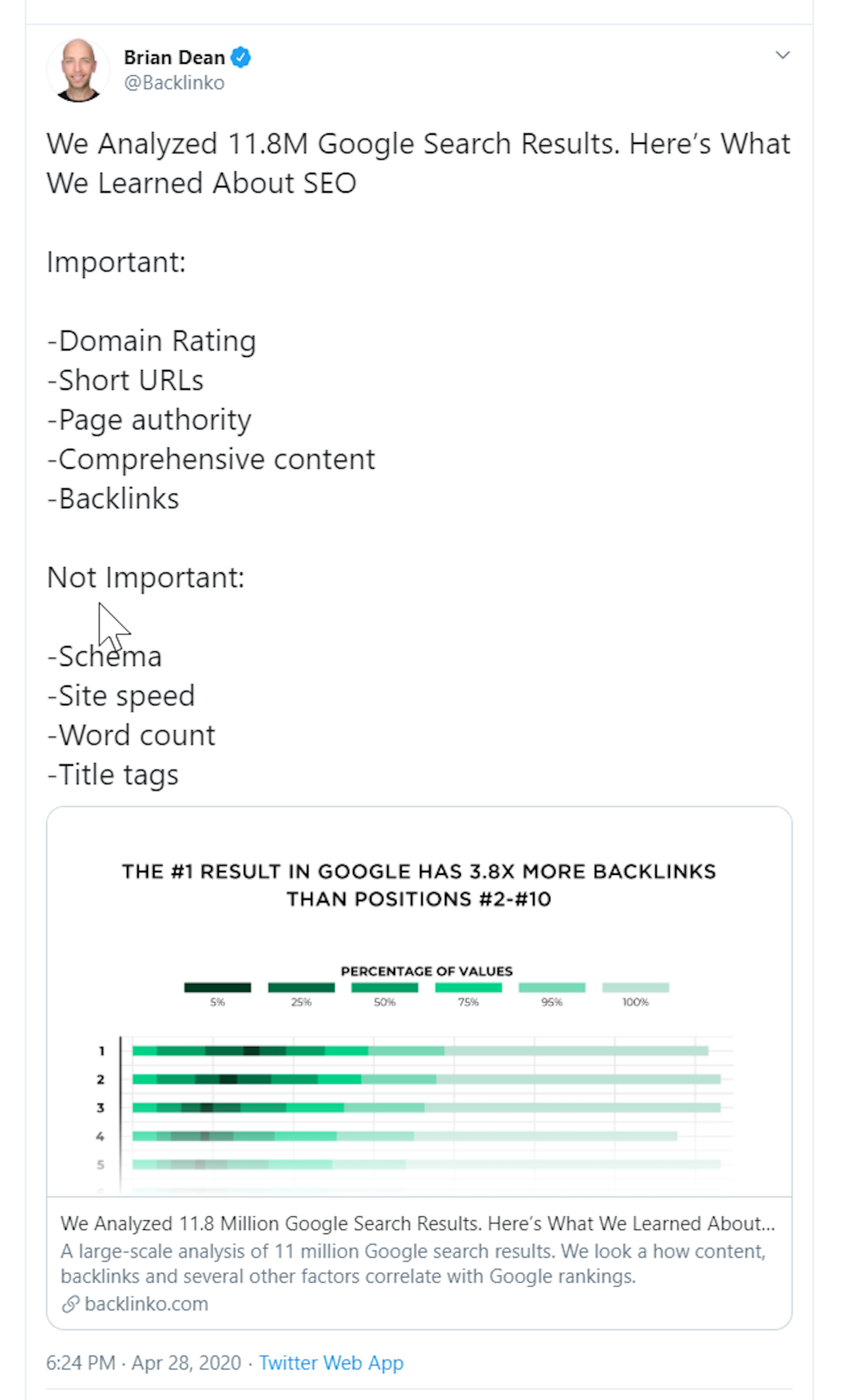
This particular study I wanted to talk about, not just because it's new, but it has generated should we say quite a lot of discussion online and even I noticed Google commenting on this article. So I'm just going to read you a little back and forth from Brian Dean and John Mueller from Google, so cutting in here straight from Google, John Mueller is saying: “While it's always fascinating to look at compilations like these, you should never assume these are or are similar to ranking factors in search.” Brian Dean came back to say, kind of in agreements this: “Google's algorithm is infinitely complicated compared to an analysis like this. This is more to shed a bit of light on how some of Google's ranking factors might work and John Mueller from Google replied: “You've built complicated algorithms at scale to. You know that it's never a single calculation with static multipliers; these things are complex and changing over time. I find these reports fascinating who would have thought X but I worry that some folks assume they're useful” - which is quite the burn coming from Google, saying that he ‘worries folks assume it's useful’ and you know, I won't read out who's written these but I was looking through other comments, people saying things like you know useless correlations backed up by mostly proprietary metrics, what else could go wrong? Correlations, domain rating, low speed by Alexa, page Authority time on site I feel like it's 2012 again. And among these Dan obviously was your comment which was “Another dangerous article, can't wait to be challenged on takeaways from this in the coming weeks.” So I thought, Dan really knows his stuff, I'd love to get your opinion on this. So why do you think this article is dangerous then?
DT: Essentially, the word dangerous I apply purely to the perception and how some SEOs, some internal marketers, some internal SEOs, may perceive and utilise the information but also dangerous in the sense that, let's be fair branding has a phenomenal Youtube following, he has a phenomenal audience within the industry, within the digital ecosystem, so he also has a lot of influence in terms of visibility.
So I know from working with lots of enterprising, with large businesses, someone at C-level comes across an article like this, goes through, looks of a spark notes for cliff notes of key takeaways however you want to call it and they go, oh scheme that's not important, then about feedback back down to someone who essentially might be in product development or in a sort of development aspect which isn't related to either in house SEO or speak to the SEO vendor and that could potentially puts a blocker on a schema ticket going pro. Obviously schemers, potentially not at a direct ranking factor, but by what I mean, I'm just using schema example - my personal opinion is that it's more of an assistance notification, like if you get a large book and someone's already gone through it and popped those little coloured tabs on the side of it - you can quickly find key pieces of information and it's useful for drawing real understanding process because I don't know, but you mentioned Paul Harris, SMX 2016 talk where he talks about the phases of Google processes - all four step process, it's not necessarily for ranking phase but we know that once it's crawled and it starts to pass and wait the information, schema can be useful in my aspect and we know that faq schema, QA schema allow for rich results. We know that product schema is also relatively essential to parts of paid, product PLA listings and things like that so that could potentially block that ticket just because it's come from a perceived Authority within the industry.
MC: There's some aspects of schema right, say like recipe schema, that you need even to be eligible for those types of result, so without that, you know you've got a cooking site, if you don't mark up your recipes, you're not going to appear in those recipe rich results, are you?
DT: 100% and so taking it on that level and we've also got to be reasonable are things so we're in the article, he just goes on to say and he does use the word correlate and he does used word correlation, but it’s how things are framed and how things are packaged and to come out directly and just say, ‘important’ or ‘not important’, that can cause issues and there’s also a lot of assumptions made in how people perceive information and data and not just how we perceive this, but how they perceive everything else. Not wanting to go massively philosophical or anything, well I remember one when I was doing a-levels I, for some reason, did a philosophy a level but one of the key takeaways from that is what's called the allegory of the cave, which was basically a publication by Plato and the long, the short of that is essentially it's a dark cave, everything this dark, they can't look at anything apart from a wall, but all they can see shadows of things cast on this wall. So it's about being able to actually see things and then what we actually perceive through sensory. So with articles like this, depending potentially even your inclination to dig deeper, your inclination to read counter points, your inclination to investigate and use your own experience, that's why I frame it with the word dangerous in my sensor. I know for a fact that I've worked with some people in the past and their site could be slow, like slower than someone running through like cold treacle and because these articles come out will challenge and say why are we spending X amount on every source to improve site speed when it's not important.
That's not coming from a place of so - essentially yeah, it comes from a place of ignorance in the sense that they don’t actually know what it means. We know besides speed is a small ranking factor and we know but if a site is slow as heck it will struggle in search results because nobody wants a slow experience and Google don't want to give bad results in my sense.
MC: I was going to say, that was something that particularly interested me actually was the kind of response from the SEO community to this, was a lot of people picked up on site speed and it sounds like from what you're saying, at least you'll hopefully or maybe not if you're not maybe great, be in agreement with, at least my understanding, which was from what I've seen that Google said about site speed is two main things which is firstly, they've quite clearly said, as far as I can see, that it's treated on a factor of, they're only really applying this when you've got, like you said “a slow as heck” maybe versus like a normal operating site, so it doesn't seem that they're applying these site speeds, if you want to say ranking factors between sites that you know take one second and two seconds or two seconds of three point five seconds to load, it’s really coming in when a sites taking three seconds versus one that's taking 15. And the other thing I think they've quite clearly stated, which you're getting to is that site speed is an on the fence kind of factor, so if everything else is roughly equal it's like the cherry on top because it's going to be a nicer experience for the user, were you surprised at all at the reaction that came from the new things? A lot of people are saying that hey site speeds super important and lastly to put on the end that, I mean not to say site speed isn't important you know as a general thing, it's critically important, but purely from an SEO perspective, you know I don't even think SEO is the right way to attack site speed that should be a conversation you're having about financials or with conversion teams, that kind of thing. But what are your thoughts to the response we saw on site speed?
DT: I mean I definitely feel, I mean as well as I speed being a ranking factor, I definitely feel that improving the speed of a website can correlate with improvement, generally of how the site performs. and that not necessarily might be in my logic we say you were the straight three second the four second marker, but it's surely by logic if you're improving the speed in which assets are delivered, you're loading with critical CSS, you’re improving TTI's, you’re improving TTFB, you’re improving all those other factors you're actually also making the easier and less stressful for Google's crawl your website, meaning you can potentially crawl more with its final scope of when it approaches your site, so it's not so much by ranking but is also just improving the general health of it and how that all builds out. Things like that, we don't really monitor, we look at a website we say that takes 5.3 seconds to load, we did some stuff, that became 3.4, we might see an increase in conversion rate, we might see an increase on other stuff at least, it’s not just that one factor that changed, as I say by shedding the weight you're also making it easier for people to crawl, you're making it easy for users load and it's a nice cycle.
For me, to say it's not important that also then comes down to what I think is a flaw in the actual study itself and it's great that you've analysed 11.8 million search results - to do that, I cannot comprehend a phenomenal amount of manpower because I mean we did a Salesforce study earlier this year where I looked at just over 1,900 websites and the amount of times where I sat there like praying for it to end just because of how long it took to process how much data, was painful, so to do that on that scale, that's a lot of computing power and that's a lot of manpower, so fair enough, but for me if you take 11.8 million search results, you might as well have gone into a supermarket and got one of every item off the shelf, opened it, and put it all in a big pot and cooked it together and then asked if it's a nice meal…
MC: Okay, I think I see what you're getting at here, so this is a way you’re suggesting that could improve the study?
DT: Yeah I mean with 11.8 million search results, there was going to be a lot of different intent, there's gonna be a lot of different seasonality factors, there's gonna be a lot of different industries. So when we come out and say there were over 11.8 million results, domain rating is the important factor for example. Well only that 11.8 million, depending on what the queries are, depending on that, potentially how many of them were brand, how many of them we're like - so I mean one of the articles I wrote on my site outranks search engine land and SC round table, the contents longer, the domain rating is a lot lower, URLs a lot longer, page authority is lower and it hasn't got anyway near as many backlinks to that domain, so I've only got one out of the four things, yet it still ranks.
For me, to put that much data into a single bowl and call it the data suit, it makes it implausible to draw any real conclusion from that. If it was that we looked at 11.8 million search results broken down by category, so here's some from finance, here’s some from travel, here are some from sport for example on news publishing results, then you can actually starts looking and go, well the intent is very different - so you can say in travel, people are either looking to book or they’re wanderlusting. So you can automatically - well that’s a very top level generalisation admittedly - but you can actually start to break it down.
Whereas if you're starting to compare a Bermuda travel landing page, versus an analysis of whether or not CTR is a ranking factor, versus how long to boil an egg, you’re going to get very different results but all three of those are potentially going to perform well within their own individual SERPs, within their own individual areas. So it then kind of comes down to where we’ve had studies in the past, which turn around and say it's like direct traffic, most websites that rank well have a lot of high direct traffic and I know a couple of tools that have produced studies like that before and it's like well yeah, if you're a major brand chances are are people gonna search for you, like the exact match and people are going to go direct to you, because if you go to a website and you like it you go back to that website, you don't necessarily have to Google it because your chrome browser remembers it.
So it's just things like that where the study, initially for me, slightly flawed and then frames the findings dangerously.
MC: I think you've really hit the nail on the head there; one of the core ways that SEOs, marketers trip themselves up, especially when they talk about ranking factors which is, it does often get overlooked that a lot of these can be very specific to different industries, verticals, niches.
So like you mentioned there for instance, one you hear quite regularly is that Google needs fresh content for instance and if you look at two extremes, let's say a newspaper site as an example, you know of course the chronological order in which they're posted is you know probably one of the most important ranking factors because it's news, right it's got to be new - but if you compare that to maybe a site that you know archives scientific papers, you know the the actual date which they're published isn't it so important it's all because if you're searching for a specific paper, you're searching for that paper, so whenever it was published, is just when it was published. So those two things you know how the new content massively impacts the ranking in two different ways. So there's a really interesting point - maybe people should take that away just with their general SEO as well as when they're looking at results of correlation studies like these.
I agree with you as well. So I think my initial reaction was, you know, I saw the tweet go out with these bullet points and it did raise an eyebrow of like “oh no” when you just see things like ‘title tag, site speed, not important’ and I think I had the same fears as you. Having read through the report, I think it does do a good job of highlighting that it is quite clearly saying this is a correlation study and it does give some quite good descriptions of the data they’ve got.
One thing I do want to talk about with you is the first result they get back on this study, and that is, our data shows that a site overall link Authority, as measured by hrefs domain ratings, strongly correlates with higher rankings. So for those that don't know the domain rating is a proprietary metric made by Ahrefs, and this is their definition of it: “Domain rating looks at the quality and quantity of external backlinks to a website. Here’s how we calculate this metric in simple terms; one, look at how many unique domains link to the target website. Two, look at the quote unquote authority of these linking domains. Three, take into account how many unique domains each of those sites links to. Four, apply some math and coding magic to calculate the R scores. Five, plot these scores on a 100-point scale.”

So what's your opinion on using proprietary metrics? Like ahrefs, domain rating in studies like these?
DT: Being honest, whenever we do comparisons to competitors, whenever we do comparisons for anything else, proprietary metrics are really the only thing we have to go off, because we don't have access to competitors Google Analytics, we don't have access to their search consoles, we can't monitor it. So what, for me with proprietary metrics, is too important to say is very indicative and it's also to understand and respect the data accuracy and the limitations of those third-party tools. For example - so this is an example from a couple years ago with SemRush, working with someone who was happy, rankings going up, ranking first, looked in SemRush and he's saying, oh well how come your rankings are different for rankings I'm getting in SemRush. So it wasn't a rank tracking tool, it was SemRush’s data warehouse, where essentially, you go in and you see a list of keywords positions etc.
Well, then what I noticed is there's a refresh date on most keywords as well and I mean it was quite niche, it was a UK niche so I mean it was relatively low search volume, we were ranking first. SemRush hadn't refreshed in four months and still was reporting fifth, so I'm looking at that and going all, well that data point is instantly out by four months and yeah, I appreciate when you've got a database of 17 billion keywords, it's not going to be real time, it's gonna be nearly impossible for any of these tools to remain real-time and we’ve all seen it in the past where things update retrospectively. I've definitely seen it with SemRush trend graphs where randomly the numbers change from previous months, but that’s just because they’re actually updating things over time, and similarly with things like Ahrefs which is a good tool, they're useful as research tools - I mean I never take for verbatim - I mean for example, I've just put in your agency site versus my site and based on this study, I've got more unique referring domains than you, do I rank for anything anywhere near as much as what you guys do? No, but it's just another metric to take his sort of goings for maintenance of research but you know, I never in my opinion think, we should be looked at similar to other tools like SimilarWeb, SISTRIX, and go right well this is definitely what's happening and this is definitely how we plan and do the strategy around things. It's more a case of, so well here's the trend we’ve seen, it's typically the trends are accurate in a sense of going up or down, and you can also perform some gap analysis of it, especially with things like backlinks but yeah for me, we're not a verbatim tool and I'm sure you've seen as well, we have agencies that basically just rely on these tools, rely on the auditing process these tools provide and rely on that as basically the service they provide and that again, without trying to fall short in my opinion of what actually SEO and being a consultant is.
MC: Yeah I know, I completely agree with you. I've seen both sides of this argument before, where some people are taking the position that you shouldn't use proprietary metrics because obviously they're not what Google or Bing or whoever is using and like I said I've seen the complete other end where just everything is blindly based on them and yeah I think they're mostly who is this middle root of - I think they are very helpful tools, especially in terms of time saving because they are looking at things that - I think for me the sweet spot is where you have strong correlations, but it also makes sense in terms of it goes - we're looking at things in this report that don't surprise us, things like page independent ranking factors like if it has lots of domains linking to it -that's correlated to the higher ranking, I don't think anyone's going to be surprised by that. You know and they also can help us try and measure the impact of that and all of these things go hand in hand, for you know these tools are looking at how many links does the site that links to us have, which is going to be loosely based on page rank and they're looking at the topics of the side, so when you get these proprietary metrics that line up with the logic, I think they are useful time savers.
One data point that did interest me actually was the site speed there and have you ever used Alexa for site speed before? Did you know that was a thing?
DT: I vaguely remember it being a thing four years ago because I did have a client once who was adamant one of our metrics of success was being ranked in the top 10,000 Alexa sites to which I was confused as heck, but yeah for me there’s two things to that. One, I don't particularly understand why Alexa was used, especially if you've got a list of domains, which they will have if they've looked into domain rating, so I've got about data point, then you can run lighthouse from a command line and you can I mean, okay it'll take a while, but I've been when I did for self my sales floor study, I just put a map book in the corner and just left it on for five days, just churning over. Well I did the site's speed thing with lighthouse three times, so I got more results soI could basically average them out, rather than just go “oh it says this, let's go” about but yeah that confuses me. But I also think because they also use time on site potentially, well no they did use time on site as well as metrics, that potentially came from Alexa as well and we know the limitations of the Alexa plug-in and for me, Alexa falls into the same category as sort of a SimilarWeb data points, it's not holistic enough to be representative of a large sample size - certainly not a sample size that large.
MC: Hmm, so was there anything in the in-depth report that you actually thought was helpful or correct or things that have done particularly well?
DT: I mean the actual methodology behind it isn't massively explained. I mean they did a summary of the key findings and they kind of explained where they got it from and I appreciate I'm just giving criticism and without looking back at the studies I've done potentially I haven't done either.
But when you look at something like ahref domain ratings, you have a look at the graph, you can see it's all nice there. For me once you get that level of data and don't distinguish it, it kind of becomes almost nonsensical, in the sense that you're looking at so many different - like we've said previously - we're looking at so many different intents, so many different page types, so many different everything, but there’s no - if it explained that here's your 11.8 million queries, this is the breakdown of the sectors, a breakdown of results sort of by sector, that can work out pretty well.
But I mean, to say for example, the average URL on Google's first page 66 characters long, for me someone can read that in house who potentially hasn't got the same breadth of experience as a lot of other people may have and then automatically, I'm spending time or potentially doing unnecessary redirects on URLs that have been 75 to 80 characters long just to get them up down below 66 or to 66, it's kind of like that magic number when we used to think for 500 words of content would be panda safe and things like that it's a numbers lying fad which don't overly work especially in studies like this, in my opinion. And then in general, the average time on site for a Google first page result is 2.5 minutes - well in my experience and I mean, we've done some good content pieces with people in the past and they’ve have had nice long form content hub centres - based on a video on that page, the video last about two minutes in length guess what - if you put a summary video at the top of the page, people are going to realise there was about 1,500 words on it or watch a 2 minute summary video. People watched the two minute summary video, analytics, time spent on site went down to below two minutes, did it make the blindest difference? No, because end of the day, the content is the content, very similarly and this for me also then produces horrible churn content and I'm noticing a lot of a moment, on things like Google discover, where it will say something oh it will be like an article with one piece of information in it and you’ll go to a news website and they'll write two paragraphs explaining what it is we're about to tell you and why then they’ll be an advert and then will be another paragraph, basically rewriting what one of the paragraphs was and before you know it, you've got about 400 words of content for what could have been a sentence and yep you do about a) because they want to drag it out so you see more adverts, but also I do wonder how much that conversation is also someone, somewhere, saying we need bits and more number of words or we need this length to be XYZ, with a natural search results.
MC: Well that was one thing that made me happy at least in the correlation report, which was they said that there wasn't any particular correlation with the word count, so hopefully, at least if we could focus on that we can just bury that one.
DT: Yeah, well I hope at least the panda thing, well not the panda thing necessarily but the actual notion of a panda safe number of text is long gone. Well then what does make an issue is how people interpret the word comprehensive, because comprehensive and comprehension can be interpreted as length, which again can just feed back into that cycle.
MC: Yeah I think that's a really good point actually, about how people are actually understanding the words that people use, like comprehensive, that’s an interesting point.
One tweet I saw from Rand Fishkin kind of summarised I think what was going on here. so we obviously had all these different points of some people quite heavily criticizing the report, people calling it a sales piece, other people saying that it's useful to have this data out there and he said, “It seems like a framing problem. Frame A, these factors are what Google uses to rank or frame B, high ranking sites tend to differentiate themselves based on these factors.” So he's saying frame A is wrong even if the data is great, frame B could be useful for a lot of people. I mean is that something you'd broadly agree with in terms of this report?
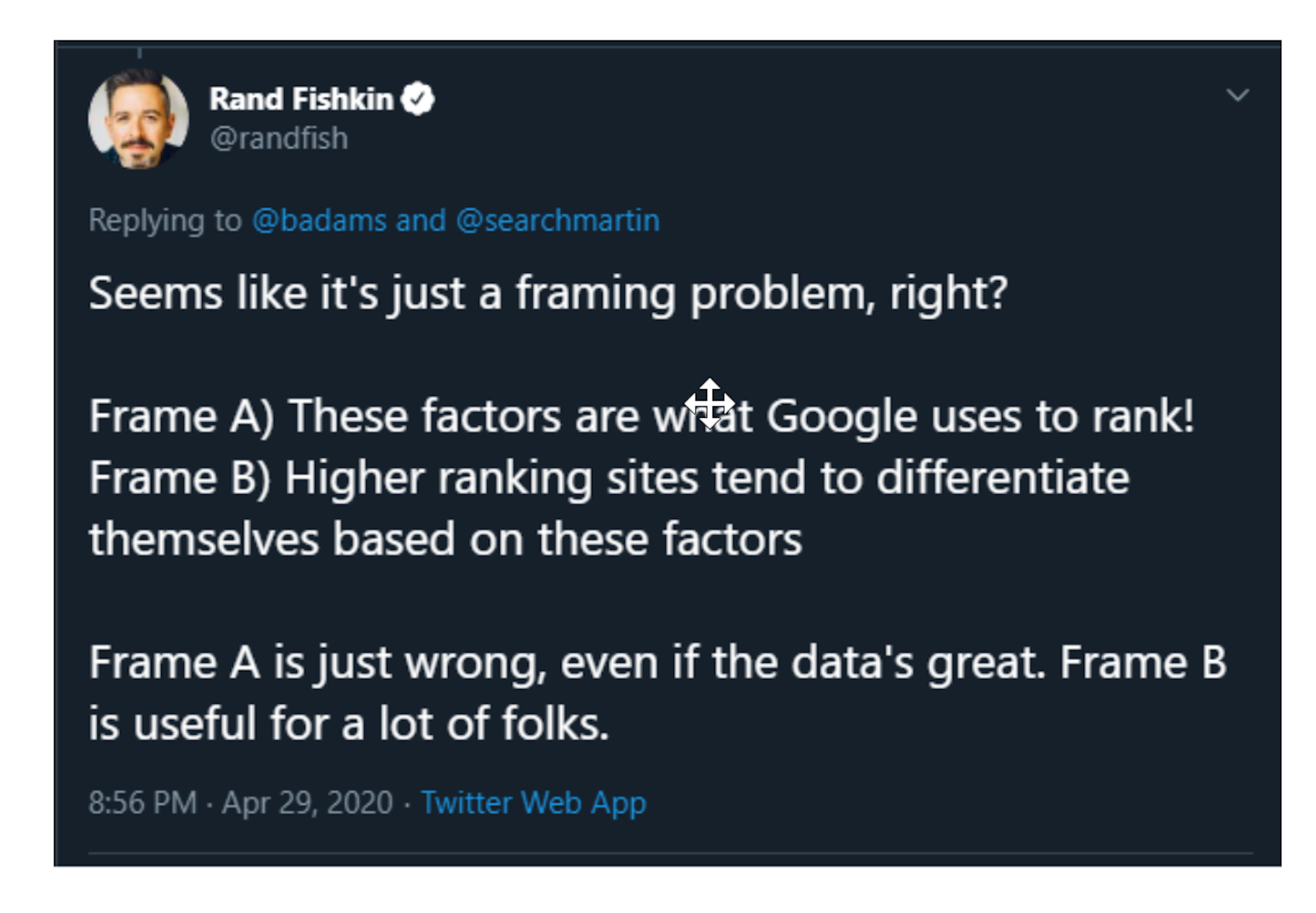
DT: Being honest, in terms of any kind of report, I’d probably - I mean for generalised report like this, where it's a big cacophony of data, with no breakdown of industries, intents, things like that, I'd argue at both frame A and B, as presented by Rand there, aren't useful for anyone, because if you say frame A are four factors that Google uses to rank, yeah that's just plain wrong, that's just outrageously incorrect - well then by saying higher ranking sites tend to differentiate themselves based on these factors, that's potentially also wrong because whilst the data correlated with that potential across this11.8 million, if you break it down by industry, you break that down by other sectors - I mean we know as SEOs for example, for ten years ago for us, words are hard but for quite a large period over last of ten fifteen years the online gambling and betting industry for example were just mad for links, all they really wanted and cared about was just driving as many backlinks as humanly possible. The content side things didn't really come into it, but then what this doesn't take into account is a fact that a lot of really highly competitive keywords, especially commercial keywords, have really large websites ranking for them.
So if you're a large brand, you'll do this thing outside of SEO called marketing and if you do marketing, such as sponsorships, television advertising, people know about you and people find you and it's exactly the same reason, if someone said if someone searching for soda and fizzy Pop, and I see your search results page without Coca-Cola, something's wrong because that's a phenomenally massively global brand but that website might be slow as heck, it might be completely angular and not renderable, but people still expect to see because that's a positive search result and positive search result isn't just defined by the metrics, it is defined by what goes into it as well and when you have a study this large, without that split amount differentiation, was going to be a massive element about going into it as well and how it brand works.
So I mean a classic example of base is spam, the canned food, they originally started off Austin, not Texas but somewhere up north, like Austin Winconsin or something and fought against a lot of stigma and stuff, but then they only really kind of became popular and acknowledged the fact that people disliked it, and when it was used as a food source for the US military they got hate mail from people within them, actively serving in the military saying, please stop producing recently something else it became a joke, they only really got to level of popularity, got that sort of canned food acknowledged when when they prosecuted the Muppet Show for basically doing a skit about them and making fun of them. That level of branding can change things, and that also lends itself to changes in the real world.
So the 2016 Bing cyberattack, for example, that changed a lot of industries and a lot of search results on its head completely because previously people searching for things like DDoS mitigation, the CDNs and cyber security were us, there were people like us - InfoSec people, there were sysadmin’s, there were technical people, they weren't average people on the street, but when you have a massive cyber attack that takes down Twitter, Amazon, Netflix, and the White House actually issues a statement about it because of how much were a public issue it's become, Google reframes on search results around that intent. So even to this day, those kind of search results are now dominated by almost layperson results, for the news and differentiations and not the commercial side, so that impacts fingers as well quite heavily and John Mueller, as you described earlier, did sum it up with that these things are too complex and change over time. They're fascinating, it's a great snapshot, but I also then tend to think how when this data was taken as a snapshot, and when it was analyzed, was that pre the current situation going on in the world right now? Because I beg to differ about a lot of research behaviors, a lot of this might have changed, and also when you look at this without intent and without actual seasonality and other things playing a factor, because we do know but seasonality can also play a turn in how search results appear, you kind of have to actually then ask, well are these first page results that are being pulled up actually valid? Are they useful? Or do they actually represent all but the real world and what will users search for?
MC: Dan, I normally do a key summary points at the end of these podcasts and I think you've just done a brilliant job of summarising John Bueller's original comments on complexity, right the way through to rands summary and why it's incorrect in context to everything we've talked about and I don't think I could face it any better than you have.
Thank you so much for giving me your time, coming on and talking to us. I think a lot of people are going to find your thoughts on this study really helpful, in terms of how they frame it, how they talk to you about it and hopefully all actions come out at the end of it. So thank you so much for that, I really appreciate it.
DT: Thank you for having me.
MC: I've learned something, I mean you know we got onto Spam suing the Muppets, which is just completely new territory to me, so I've learnt a lot as well Dan. Thank you so much.
Show notes for everyone transcription of this episode, links the stuff we talked about will be online at search.withcandour.co.uk - this episode with Dan is going out on Monday, May the 4th, Star Wars day. Are you a Star Wars fan?
DT: I am, that has actually probably made me smile more than you should have that I've got the Star Wars day episode.
MC: Top man, excellent. So we'll be back, so enjoy Star Wars day, and we'll be right in one week's time, on May 11th. Hope to catch you there.
