13.07.2020
28 min listen
With Mark Williams-Cook
Season 1 Episode 69
Episode 69: Blogspot.in, indexing low quality pages and the rich results tool

In this episode, you will hear Mark Williams-Cook talking about the Google Blogspot.in expiring: Why expiring domains are hugely valuable for SEO and how you can prevent yours from getting caught, low-quality indexing: theories on if Google has "raised the bar" on the quality of content they will index, rich results tool: the SEO community reaction to Google's new schema testing tool and SEO resources: some extra tools and resources for you to use.
Play this episode
01
Show notes
https://blog.littlewarden.com/articles/do-you-have-a-process-for-your-client-domain-names/
https://twitter.com/googlewmc/status/1280507131318460418
https://webmasters.googleblog.com/2020/07/rich-results-test-out-of-beta.html
Rob Kerry e-com podcast https://ecommerce.fm/
https://www.aleydasolis.com/en/seo-tips/
02
Transcription
MC: Welcome to episode 69 of the Search with Candour podcast. Recorded on Friday the 10th of July 2020. My name is Mark Williams-Cook and today we're gonna be talking about Google's domain expiry snafu, we're gonna be talking about indexing low quality pages in Google and if that's still a thing, and we're going to be talking about their new schema testing tool that's replacing their structured data testing tool. I've also, at the end of the show, got a few SEO resources for you, and if you haven't heard of them you'll find them very, very useful indeed.
It's a rather unfortunate situation we're going to start off with, which is Google forgot somehow to renew one of their blogspot domains - blogspot.in. So this leaves them essentially in the situation where they need to negotiate with the person that bought it, to buy it back and as the blog post on Little Warden goes further to you know point out, this isn't just Google this has happened to. So I'll read out a snippet here of some previous cases. So they've written here, a few weeks ago the UK government forgot to renew a help to buy domain name which was mentioned hundreds of times across documentation. So the UK government saw internal links or external links, in their own documentation, and it was instantly snapped up by someone and sold at auction for £40,000 and 2018, a year before last now, Clydesdale Bank had to go to court against a cyber squatter to get control of an expired domain. Although they won the domain back, it costs months of time and hundreds of thousands of pounds in legal fees. 2017, Meketa, a company worth over a billion dollars, made headlines by forgetting to renew its domain, and he said, we can go on with further examples from Microsoft, Foursquare, Microsoft again, Dallas Cowboys, Microsoft again but we won't. The point here is these are all very big brands, with very valuable domains that should know better. And if it's not something you've encountered within SEO before, it's actually quite a mature market now and that is the monitoring and drop caching of these domains.
So any domain that's been around for a while, that's attracted links and those links have been there a while, has some latent value to it and I'll link at the end of this podcast and you can find it in the show notes - a link to a particular news that it's all about buying and selling websites and building up websites and flipping them and making money from them, and one of the things a lot of people do when they start off in this endeavor is to actually buy domains with a backlink profile or domains with a history. So there's always been talk about what happens if you buy a domain and it's got links and then domain expires, you know do those links still count if you then publish a completely new website and I've certainly seen mixed messages on this from both Google and webmasters and personal experience. What I've personally experienced is that if you do manage to buy a domain with a history and you can resurrect it, if it's expired with similar or very similar content, then it will - in my experience - tend to rank a lot faster and a lot better than a fresh out of the box domain with no links. I know there are safeguards in place if you buy a domain that's in a particular topic or a niche, and you try and publish something completely different, that's probably not going to have the desired effect.
Something else that I've seen, and I know people do, is for people that run private blog networks - so that's people that are controlling whole sets of websites, where they control where the links go for SEO purposes. I've certainly seen people buy expired domains and then, they'll actually find the content that used to be on that domain through something like the web archive and just restore it. So it maybe looks like to search engines that all that's happened is the domain accidentally expired and it maybe changed who was managing it, but the old content was still there. And there's no real way for a search engine to, that I can see, to practically protect against that because if you run some very feasible scenarios such as, I own a web site and you decide to buy it from me, the who is the registration information will change and there's certainly no reason for it to lose rankings just because the owner of the domain has changed. And in a similar vein, if I own a website and I do let the domain expire and so the site goes down for a little bit and then I might whoops and I'm lucky enough where I can renew it without someone else grabbing it and it goes back up, again there's no sort of logical reason from a search engine point of view for, if it can then get back to the content and the links that exist, why necessarily it should rank a lot worse than it did before. So with these two things combined, if I did sell a domain and in the meantime it did expire briefly, again, you wouldn't expect a negative outcome from that and that externally is exactly the same as if a domain expires, someone catches it and then they restore the content from an archive. From an external point of view, that looks like the same kind of situation which I'm guessing is why people are doing it for PBNs and why it is working.
Now, there are services that already exist which are very fast to do what's called drop caching, which is essentially to place bids and purchase domains very quickly after they have expired. So it's not something you can casually get into, if it does interest you, you're not going to be able to unless you're incredibly lucky, it's very, very unlikely that you're gonna see a valuable domain to expire and sit there waiting around for someone else to renew it. It's especially the case that you'll see, if ever you've tried to register a new website or a new business name, pretty much every variation of dot com domains are gone, so of all English words and combinations of them are normally squatted by someone who was registered it for 10 pounds or whatever and then they're trying to resell it for a higher fee. So that's a very well established and old market now. And I thought it's really interesting that this did happen to Google, it's something to think about I think because it does sometimes fall between the cracks. I've seen it happen before as well where companies get websites made and there's this assumption, unless it's spoken about and unless someone says, we are taking responsibility for this, sometimes the responsibility for actually who is renewing this domain name is it the web agency, is it the IT team, is it someone in marketing in-house, sometimes falls through the cracks and when it does happen, it’s absolutely devastating. Even though it's a thing that can only happen at most once a year, depending on how long you register the domain for, it's one of those things that can be very, very expensive when it does happen.
So Little Wardens actually a tool I’ve used before, that one of the things it does monitor is domain name expiration - I'll put a link to it in the show notes at search.withcandour.co.uk, so you can check it out and it might be worth, if you haven't, double checking when your domains are going to expire. So if it can happen to them, it can certainly happen to you - that's what I got as a take away after reading about this situation where Google had forgotten to renew one of their domain names for their blogspot.
Low-quality page indexing is something I would like to talk about. so that is how difficult is it, has it changed in difficulty to get quote-unquote low quality pages indexed in Google and why you might want to do that. I'm normally pretty good on this podcast in sticking to facts, sticking to evidence, sticking to data, sticking to what Google is saying or reporting, this you'll have to give me a little bit of leeway here because this is just something I've noticed in terms of I've heard and seen three or four different things, which are leading me towards a conclusion, which may be completely wrong. you're welcome to, as always, tweet me or whatever to say if you think I'm spewing BS and it certainly happened before, but it’s something I wanted to talk about because I find it quite interesting. And this stemmed from a few weeks ago it was quite publicly visible that Google was having some issues indexing new content, and this is actually something we've covered on this podcast, I think three times now. so once this year and twice in 2019, there were you know i'd say fairly large - just in terms of the impact of webmasters noticing something was wrong - issues with how Google have been indexing content. I was listening to the Google Search off-the-record podcast, which I highly recommend and you've got John, Gary, and Martin split on there - I think they are two episodes in now, really interesting, easy listening stuff and one of the things that they spoke about on the last podcast they did was about this outage if you like, in terms of Google and crawling and indexing.
Specifically they went into a lot more detail about why this issue occurred, then I've ever kind of heard them publicly talked about before. So Gary discussed that essentially, and I'm sure it's way more complicated than this, but for the layman, what was happening was the crawlers were overwhelmingly indexing. So this means maybe Google, as I understand it, was chucking too many URLs at the indexer and the indexer was not keeping up and it was creating a bottleneck, which was creating this queue, which was creating this ever-increasing delay in new pages getting indexed. So fair enough, that's what that issue is. At roughly the same time, I noticed that Gary had also tweeted saying something like, why is it people are surprised when their low quality pages are not being included in Google's index? Because as we all hopefully know, just because your page is crawled and discovered by Google, it does not necessarily mean it will be included in the index and it will be returned in subsequent searches by users.
As a third thing, or a third and fourth thing, I had noticed - so, a colleague of mine and I had set up a couple of our little just for fun SEO experiments, we don't always publish them because they're not valid enough and don't have large enough data sets to be mega interesting or stand up well to scrutiny, but we like testing small things that are under our control - and one of the things we were testing was just looking at how quickly we could get new pages, equal pages, discovered from links, maybe that were from no indexed pages, whether the noindex was on the page or in the HTTP header and whether that would happen at all. And we set up our experiments roughly the same, but there was one kind of key difference, which was the pages that he was trying to get indexed were roughly the same as the rest of his other pages on his site, in that he had made them in the same template, they had a fair bit of content in them, and they were just linked from the home page. My experiment was a little bit different in that I had linked to these pages again from the home page, but I had just written the HTML by hand, in notepads, and there were about two sentences on each page. So it was like a super thin page, with pretty much no content on it. And we both did our experiments, and after like a few days he messaged me and said yeah, actually both of these pages got discovered and got indexed and he asked how about yours, and when I checked I was like, huh neither of mine are indexed, not even the one that we were expecting to get indexed. I left this for about another four to five weeks, so these links have definitely been discovered because they're on the homepage, the sites changed since then, other stuff got indexed and I noticed that the pages never got indexed. I didn't look into it in a huge depth, I did check the logs, they had been crawled. So I came to the conclusion that Google had decided obviously because that it was very short, very different to the rest of the site, they probably weren't worth indexing, which is again really anecdotal, but something I had noticed hadn't happened before. I've done similar tests in the past where I've created these little scrap pages and they get indexed. They don't particularly rank for anything, but they are there if I trigger a specific search, but this wasn't the case this time.
The final strand connected to this was, with an SEO client that we had been working with, we were looking at some of their competitor activity and one of the things their competitor was doing - being very careful here not to identify anyone - so this was an e-commerce website and they had taken a very aggressive approach to indexing or trying to get indexed and filtered and faceted views of their product categories. So this means they would have their product categories, their subcategories indexed in Google, however all of their filters - these were a type of item that had a size and these were the type of item that had a price range, they were making indexable pages for every size and price combination. So it was, this item at this size under 20 pounds, and item range at this size under 50 pounds, and as you can imagine there are literally thousands and thousands of different combinations for these. This technique had historically worked very well for them, looking at the amount search traffic they had got, it kind of built up and it looked like some of those longer tale pages were getting - well they were definitely indexed - and it looked like they were getting traffic; not huge amounts but that's the point, each of those pages may be only getting ten visitors a month but they were getting traffic. And I noticed at the end of April, according to - because obviously I don't have access to their analytics - but according to all of the external data sources I could get my hands on, like SemRush and SISTRIX, it looked like their site had taken a big nosedive and scratching a little bit below the surface, it looked like these pages were dropping out of the index.
So all of these things came together to bring me to the conclusion, maybe that from this bug that Google's had with the crawler overwhelming the index, with what Gary's saying like, yeah well bad pages aren't gonna make it into the index, with this experiment that I ran and with what I've seen with these competitors. My guess is that Google is getting a little bit stricture in the type of pages that it wants in its index. As you know last episode we covered the 2019 Google spam report, where we said they were encountering something like 15 billion pages per day of spam, and this is gonna go in line I guess with the amount of genuine content that is created on the web, that's massively growing. So I guess they're at the point where there is enough of this really good content to go around, there's such a volume of it, that it makes sense to reduce spam to improve search quality that they raise what is the entry level into getting pages indexed. so I think it's worth bearing in mind, if you are planning on doing a site and you're thinking about things like different filtered, faceted pages, or maybe tag pages in WordPress, that kind of thing, I think it's worth really carefully considering what is still ranking in your competitors, what does add value to the user, and whether you would like to land on that page and if it makes sense. Not sure if it's entirely a thing, it makes sense to me and the things I'm seeing seem to go in line with that, so I'll let you make your own minds up about that one.
So blogspot is a big online blogging platform, I'm sure all of you have seen at least one website on it that any user can sign up for it, it’s spread across multiple Geographic top-level.
The Google Rich results test is out of beta, as announced on the 7th of July on the Google Webmaster blog. So they posted saying, today we're announcing that the rich results test fully supports all Google Rich result features and it's out of beta. in addition we're preparing to deprecate the structured data testing tool - waving hand emoji - it will still be available for the time being but going forward we strongly recommend you use the rich results test to test and validate your structured data. and then Google goes on to say, rich results are experiences on Google search that go beyond the standard blue link, they're powered by structured data and can include carousels, images or other non textual elements, over the last couple of years we've developed the rich results test to help you test your structured data and preview your rich results. Here are some reasons the new tool will serve you better. one it shows which search results feature enhancements are valid for your markup that you're providing. Two, it handles dynamically loaded structured data markup more effectively. Three, it renders both mobile and desktop versions of a result and four, it is fully aligned with search console reports. You can use the rich results test to test a code snippet or a URL to a page the test returns error and warnings we detect on your page, note that errors disqualify your page from showing up as a rich result, while warnings might limit the appearance. Your page is still eligible for showing up as a rich result and then they go on to give some examples of that.
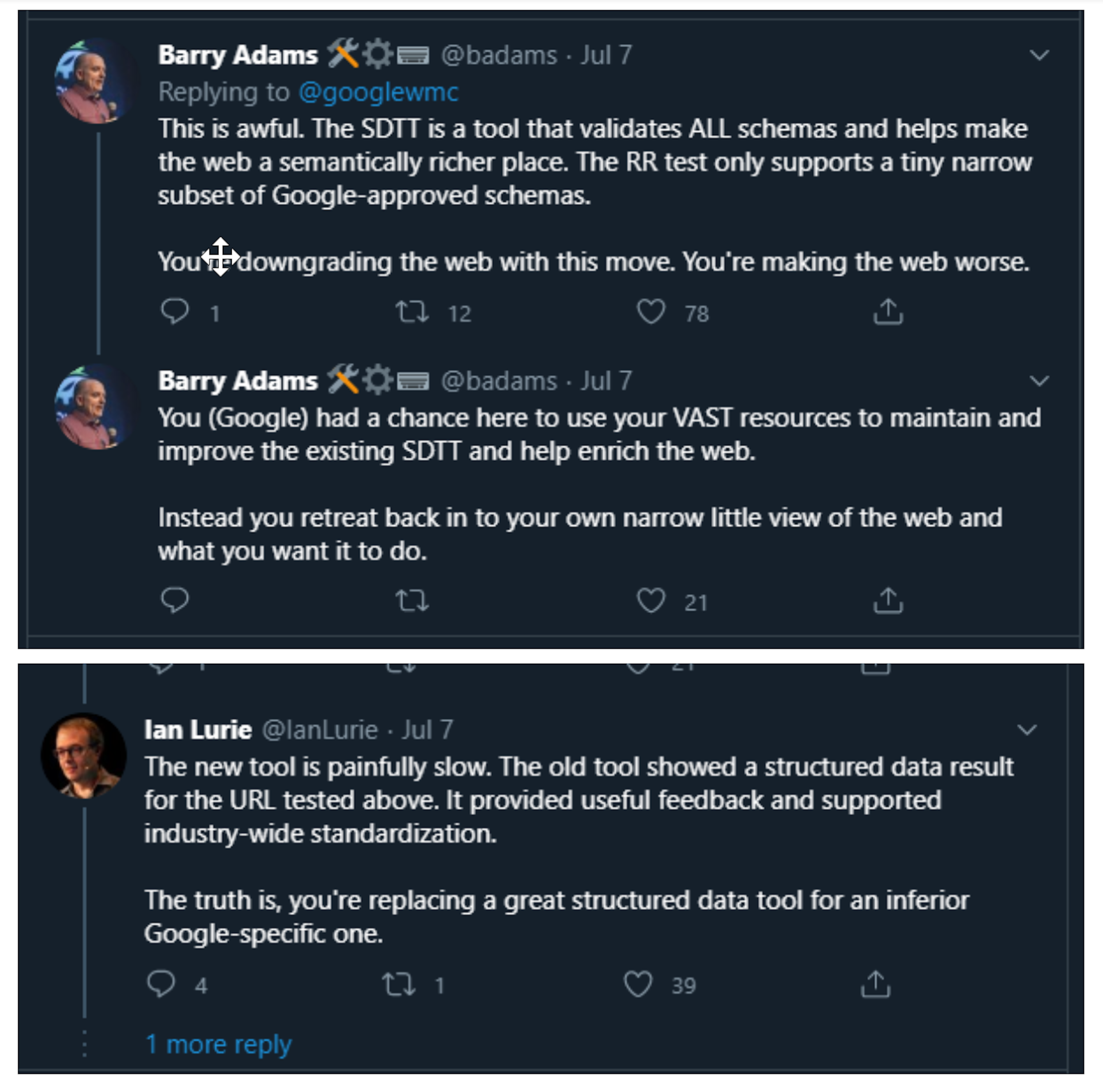
So that's no different to the structured data testing tool in terms of warnings, mean it's not going to show, and sorry errors mean it's not going to show, and warnings mean you're still eligible. so that was the announcement that went out as well the same day on Twitter. it was not met with rapturous applause by the SEO community to say the least. so the first reply that I can see in this thread is from Barry Adams, who replies to Google Webmaster central saying, this is awful the sttt, so the structured data testing tool, is a tool that validates all schemas and helps make the web a semantically richer place. the rich results test only supports a tiny narrow subset of Google approved schemers. you're downgrading the web with this move, you're making the web worse. you Google had a chance here to use your vast resources to maintain and improve the existing structured data testing tool and help enrich the web. instead you retreat back into your own narrow little view of the web and do as you want to do. So say what you really feel Barry, and so not well-received by Barry.
Again, the next comment down, Ian Lurie says, really is this better - and he's got a search result a screenshot of a rich test result saying page not eligible for rich results known by this test - so both Barry and Ian here are pointing out that this new rich results tool is ignoring the majority of action of schema that kind of exists as the standard and it's only testing for schema that Google currently provides special results for. Ian goes on to say, the new tool is painfully slow, the old tool showed a structured data result for the URL tested above. it provided useful feedback and supported industry-wide standardisation. The truth is you're replacing a great structured data tool, for an inferior Google-specific one. And I think that's been reflected, in fairness, that's the feedback a lot of webmasters are giving. which is that you know there is more to the web than Google, and their original structured data testing tool was helpful in that it could help us verify schema across the board, so not just things that Google is currently offering features for. So while that's out of beta, I know people will be looking for some alternatives, and I will talk to you about some alternatives in a second when I go through some extra SEO resources for you.
MC: Okay, SEO resources I put together a list of a few links, based on what we were talking on the show today, and just one or two other things which I think are great if you don't know about them. so starting with what we were just talking about, so this schema validation -there's a couple of other options for you. so there's two websites and I will include all of these links in the show notes at search.withcandour.co.uk - so you can just go there you'll be able to find the transcription for this podcast and you can just click on those links.
So firstly, there is schemamarkup.net, which is a great online tool that will enable you to validate all of your scheme and not just the Google Rich result to validated schema and alongside that there's another website called Schema.dev, slightly different schema.dev, it does offer a schema builder as well and it's got a Chrome extension that goes with it. It's a really helpful set of tools to help you generate schema. So if you are gonna miss the structured data testing tool, these are two things that I recommend you bookmark.
We mentioned earlier, right the beginning of the show when we were talking about domain name caching, domain name purchases, and I kind of got on to the subject of building selling flipping websites and there's a resource at richardpatey.com, which again I'll link to in the show notes, and Richard offers a free newsletter about investing in websites and building them up and there's a paid one as well. well worth checking out if that's something you're interested in.
Two other resources, I haven't covered today but are absolutely brilliant so Rob Kerry. I don't know how to introduce Rob really, if you don't know him he's definitely one of the best SEOs I've ever had the pleasure of meeting, although very briefly. I've seen some of the work he's done over more than the last decade, just take my word for it, check it out. He has started an e-commerce podcast which you can find the very nice URL of e-commerce.fm, I think he's about seven or eight episodes in now. It's brilliant, if you're involved in e-commerce or you're interested in commerce, go listen to that and subscribe.
Lastly, I guess a lot of people listening to this podcast will already know about this, because she has over five thousand subscribers to it, but Aleyda Solis runs a newsletter for SEO which I always say wrong in my head and it's SEOfomo, so SEO F O M O, which is Search Engine Optimisation, Fear Of Missing Out - I guess, if you just Google Aleyda SEOFOMO or probably just SEO FOMO, you'll find it. You can sign up, Aleyda sends out a weekly newsletter,a roundup with links of all the stuff that's happened in SEO.
It is one of the two newsletters I actually sign up for with SEO, so there's that one and I subscribe to TLDR marketing, both of these you can find just by Googling them and I'll put in the show notes but both give really fast breakdowns, not huge emails that take you ages to read. So highly recommend all of those resources.
And that's everything I've got time for in this episode, I'll be back next Monday which will be July 20th, if you're having fun please do subscribe to the podcast. As usual, you can get the transcription as well if you prefer reading at search.withcandour.co.uk. And I guess you'll hear from me in a week here.
